KONPUTAZIO ZIENTZIETAN
METODO MATEMATIKOAK 09-10
UNIVERSIDAD DEL PAIS VASCO - EUSKAL HERRIKO
UNIBERTSITATEA, UPV-EHU


PRAKTIKA I: IKASKETA
AUTOMATIKOARI HURBILKETA
 Entregatze epea:
martxoak 3, asteazkena,
laborategia baino lehen (martxoak 3-ko laborategia beste eginkizunetarako
erabiliko da)
Entregatze epea:
martxoak 3, asteazkena,
laborategia baino lehen (martxoak 3-ko laborategia beste eginkizunetarako
erabiliko da)
===== Entregatzeko forma ===== Iñaki Inzari (bere bulegoan edo
laborategietan), inprimatuta, letra tamaina 12pt,
txukuntasuna, izena eta e-maila lehen orriaren goiko partean.
Plastikozko funda
batetan, mesedez: hor ere sartuko ditut zuen hurrengo praktikak
Kurtso guztian zehar behin eta
berriz ikusiko dugunez, 80 eta 90-ko hamarkadetan
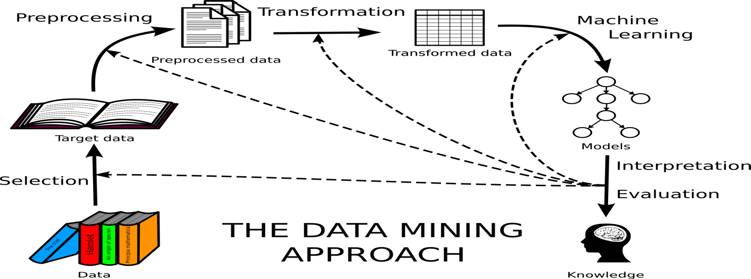
"Data Warehouse"
izeneko disziplinaren izugarrizko gorakada ikusi genuen, ordenagailuen kalkulu
potentzi eta datu bilketaren hobekuntzaren parean: datu baseak, datuak gorde,
kalkulu orrietan, SQL-n, flash memoriak, etc.
Baina 90. hamarkadaren bukaeran beste galdera ausartago bat
plazaratu zen: datuak soilik gorde eta zer gehiago? zer egin datu horiekin?
zertarako gorde datuak? kolekzionismo hutsa? datu horietatik zerbait atera-ikasi
daiteke, gure begi-bistak esan ezin diguna? Problemaren konozimendu gehiago,
pista gehiago atera al daitezke ("Knowledge discovery"). Horren inguruan, sekulako
indarrarekin agertu da "Data
Mining" disziplina.
Disziplina honen inguruan, El
Pais egunkariak orain dela gutxi
ondoko artikulua publikatu zuen, "Data Mining"-aren laburpen polita eginez,
eta "Numerati" liburuaren
aurkezpena eginez.
[Galdera 1 -- Irakurketak --
Ikasketa Automatikoaren aplikazio errealak] -
Hurrengo loturetan nere
atentzioa deitu duten hainbat artikulu dibulgatibo daude, era errazean idatziak,
"Data Mining-aren" hainbat aplikazio ulerkor aipatzen dituztenak:
- supermerkatuetan erosketak:
haur-oihalak (pañaleak) eta garagardoa. Noizbait
planteatu al diozu zure buruari ondokoak: ba al daude supermerkatuetako
produktuak zoriz ordenatuak pasilloetan? Supermerkatuek ofertan jartzen
dituzten produktuak erlazionatutak al daude? Abantailik ateratzen al dute "Travel
Club" erako txartelekin supermerkatu handiek? Zertarako jakin nahi gure datu
pertsonalak eta zein erosketa egiten ditugun, zein produktu erosten ditugun?...
- birus-informatikoen beste bariante bat bezala,
"malware" programak eta fitxategiak detektatzeko
- gure arerioek
poker-eko Internet-eko on-line partiden estiloa ikertu nahian, arerioen
jokatzeko estiloaren gainean ikasketa automatikoa aplikatu nahian beraien
jokatzeko era jakiteko...
-
noiz erosi
"low cost flight company batetan" billeteak? (kuriosidade
bezala, orain dela gutxi Microsoft-ek erosi zuen artikuluan
erreferentziatzen den "Farecast" enpresa)
Banan banan irakurri eta
bakoitzarentzat hurrengo galderei erantzun:
- zein da ebatzi nahi duten problema (predizitu
nahi duten gertaera-aldagaia)?
- ba al dute erabilitako aldagai prediktoreek
informazio nahikoa predikzio zihurrak egiteko? uste al duzu kasu-exenplu nahiko izango al ditugu
modelo zihurrak-solidoak eraikitzeko?
- antzematen al duzu "non dauden" datuak, hau
da, "nondik ateratzen-sortzen" diren datuak?
- iruditzen al zaizu mundu errealean aplikazio
honek erabilgarritasunik duenik?
- zergatik da beharrezkoa "data mining" egitea,
datu analisia? ez al dago gizaki jakitunik non zihurtasun osoz klasifika
ditzaken kasu berriak?
- eta abar...
[Galdera 2 -- Data Mining-eko
problema baten proposamena] -
Aurreko irakurketak egin eta
gero, praktika honen bigarren galdera bezala eskatzen dizut proposatzeko, zure
intuizioan oinarrituta, problema bat non bere gainean "Data Warehouse -- Data mining
-- Knowledge discovery" katea egitea zentzua izango zuen:
- zein utilidadea izango zuen? gizakiek
begiz ikus ezin dezakegun zer nolako jakinduri mota egon daiteke
datuetan?...
- nondik jasotzen dituzu datuak? (web-a,
formularioak, inkestak...)
- zergatik da beharrezkoa "data mining" egitea,
datu analisia? ez al dago gizaki jakitunik non zihurtasun osoz klasifika
ditzaken kasu berriak?
- eman itzazu zure intuizioa oinarritzen
duten eta bisitatu dituzun Internet-eko helbideak
[Galdera 3 -- Data mining-aren ingelesezko definizio eta
oinarrizko
kontzeptuak] --
Stanford-eko
Unibertsitateko web orri honetan ikasketa automatikoko ("machine
learning") hainbat oinarrizko terminoen definizioak agertzen dira. Hauetako
askok kurtso guztian zehar behin eta berriz erabiliko ditugu.
Laburki, euskaraz defini itzazu ondoko terminoak,
kontutan izanda klase teorikoetan jasotako informazioa, eta ere eman ezazu
euskaraz klasetan erabiltzen dugu terminoaren izena (diferentea izan ezkeroz):
accuracy, attribute-feature, aldagai motak (categorical,
continuous), classifier, confusion matrix, true positive rate, false
positive rate, cross-validation, data cleaning, data mining, instance,
knowledge discovery, machine learning, missing value, model, supervised
learning.