====
WEKA
formatoko datubaseak: kurtso guztian zehar eta praktika guztietarako erabil
itzazu ====
[Galdera 1 -- Data mining-eko datubaseen
explikazioa -- Datuen natura] --
Goiko parteko loturan kurtsoan zehar WEKA softwarearekin lan egin ditzakezun
hainbat datubase kokatu ditut. Datubase hauek jadanik WEKA-ren *.arff ("attribute
relation format file") formatuan daude. Kurtsoan zehar egingo ditugun
ariketetan bai datubasea zuk aukeratu, edo nik proposatuko dizuet. Hala ere,
datubase hauek "azpitik duten datu analisi problema" ulertzea lagunduko
dizue. Horrela, 2-3 datubaseen natura ondo ulertzea gomendatzen dizuet
kurtsoan zehar egin beharreko ariketak burutzeko, eta joan zaitezke horrela
aldatzen lan-datubasea.
Proposatutakoen artean 2 datubase
aukera itzazu, eta bakoitzarentzat hurrengo puntuak agertu (ondoko
informazioaren parte haundi bat *.arff fitxategiaren goiko partean topa
dezakezu, edota UCI
datubase kolekzioan *.names luzapeneko fitxategian):
- agertzen duten problemaren natura,
oinarria, zergatia agertu
- zein da burutu nahi den sailkapen
problema? zein da klasea ("problem class, class to be
predicted")? Labur explikatu klaseak har ditzakeen balio desberdinak,
eta balio bakoitzarentzat dagoen kasu kopurua (klasearen balioen
distribuzioa)
- ulertzen dituzun ahalik eta aldagai
prediktore ("features", "predictors", "variables") gehienak labur
explika itzazu
- datubasearen problemaren inguruan
atentzioa deitu dizun beste edozein puntu: zergatik aukeratu dituzu
hauek eta ez beste batzuk?
[Galdera 2 -- K-NN sailkatzailea] --
WEKA softwareak
K-NN sailkatzaileak "Lazy" familiaren barruan biltzen ditu.
WEKA-ren IBk metodoak K-NN sailkatzaileak inplementatzen ditu.
Zer esan nahi du "Lazy" ingelesez?
Zergatik uste duzu WEKA-k biltzen dituela sailkatzaile mota hauek "Lazy"
izenaren barruan? Hau da, sailkatua
izateko kasu bat etorri baino lehen, K-NN sailkatzaile batek "lan" egin al
du? Modeloren bat ikasia al zegoen aldez aurretik, sailkatua izateko kasu
bat etorri baino lehen?
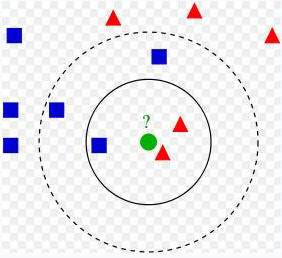

[Galdera 3 -- K-NN sailkatzailea --
Aldagaien Pisaketa -- "Feature Weighting"] -- Weka-ren IB1
sailkatzaileak bizilagun hurbilena soilik erabiltzen du sailkapenarako. IBk
sailkatzaileak ordea, etiketatu gabeko kasu berriaren klasea predizitzeko,
kasu honen entrenamendu fitxategian dauden k bizilagun hurbilenak
konputatzen ditu lehenago. Hori egin eta gero, klase teorikoetan ikusi duzu
bariante asko daudela, IBk-ren parametroen balioen arabera.
IBk
sailkatzailearen ondoko parametroak esplika itzazu: KNN, "distanceWeighting",
"noNormalization".
Esplika itzazu "distanceWeighting" parametroaren balio posible guztiak: "NoDistanceWeighting",
"Weight by 1/distance", "Weight by 1 - distance" (metodo baten parametroak
ikusteko klikatu metodoaren negritaz dagoen izenean, eta gero "More" botoia).
Zer inplikatzen du "Weight by 1/distance" egiteak (esplikatu laburki,
adibide batekin)? Asmatze tasak (ondo sailkatutakoen estimazioa, "predictive accuracy")
berdinak al dira "distanceWeighting" parametroaren balio desberdin
guztietarako (hartu nahi duzun
problema WEKA formatoan)? Zergatik?
[Galdera 4 -- Datuen preprozesamendua --
Aldagaiak Normalizatu -- Normalize --- K-NN
sailkatzailea] -- Datuen preprozesamendua: datuetan oinarritutako
edozein sailkatzaile edo modelo eraiki baino lehen, ezinbestekoa da datu
originalak, datu gordinak ("raw data") preprozesatzea, hainbat
zentzuzko moldaketa "intuitibo" egitea: ezin da normalean datu gordinak
hartu eta hasi besterik gabe sailkatzaileak eraikitzen.
WEKA softwareak preprozesuko eragiketa guzti
hauek bere lehen lan leihoan ("pestañan") kokatzen ditu, "Filter" barruan (WEKA-k
interpretatzen ditu datuen gainean aplikatzen diren "filtroak" bezala). "Filter"
konkretua aukeratu eta gero, eragina izateko datubasearen gainean "Apply"
botoia sakatu behar da. "Filter" hauek banatzen ditu "supervised" (sailkapen
gainbegiratua) eta "unsupervised" (sailkapen gainbegiratu gabea) artean,
predizitu nahi den aldagaiak (klase aldagaia) jokatzen duen paperaren
arabera.
Aldagaiak normalizatzea ("Normalize")
preprozesuko eragiketa klasikoa da machine learning-en (Unsupervised -->
attribute). Aukera ezazu
zenbakizko ("ordinala") aldagairen bat duen
WEKA
formatuko datubase bat, eta ikertu zein eragina duen beraiengan "normalize"
funtzioa aplikatzeak:
- Nola aldatu dira aldagaien balioak?
- Uste al duzu K-NN
sailkatzaileak defektuz eragiketa hau aplikatzen duela?
- K-NN sailkatzaile
bat aplikatzea "normalize" "filter-a" aplikatu gabe edo aplikatuta asmatze
tasa berdinak al ditu?
- Zergatik uste duzu beharrezkoa dela K-NN
sailkatzailearentzako filtro hau aplikatzea?
[Galdera 5 -- Aldagaien diskretizazioa --
Datu preprozesamendua --- Discretize --- K-NN
sailkatzailea] -- Gure datuetako balio numerikoak dituzten aldagaiak
diskretizatzea ezinbestekoa da ikasketa automatiko eta data mining-eko
aplikazio eta egoera askotan. Sailkatzaile mota askok ere ezin dezaketa
balio numeriko jarraiekin ("continuous") lan egin, eta horrelakoak diren
aldagaiak ("feature") diskretizatu behar dira. K-NN sailkatzaileek bi motako
aldagaiekin lan egin dezakete auzokideen arteko distantziak kalkulatzeko
momentuan:
- aldagaiak "orden" izaera bat duenean ("ordinal"
edo "continuous" erabiltzen dira ere izendatzeko), hau da,
"orden" kontzeptu bat dagoenean bere balioen azpitik, normalizatu
eta gero, distantzi Euklidearra erabiltzen da aldagai
horren bi balioen arteko distantzia kalkulatzeko. Era horretan,
distantzi maximoa 1 da, minimoa aldiz 0.
- aldagaiek ez dutenean ordenik,
"nominal" izenaz ere ezagutzen dira ("discrete" bezala ere): "izenek"
("nombres"-"nominal") definitzen dituzte bere balioak (koloreak,
adibidez). Aldagai mota honentzat ezin da distantzia Euklidearra
erabili bere bi balioen arteko distantzia kalkulatzeko. Normalean
"overlap" izenez ezagutzen den distantzia erabiltzen da bere
bi balioen arteko distanzia kalkulatzeko:
- bi balioak berdinak badira (A=A),
orduan distanzia 0 da;
- bi balioak desberdinak badira
(A≠B),
orduan distanzia 1 da.
WEKA formatoan dagoen eta bere aldagairen
batzuk ordinalak-continuous ("Real", WEKA-n) diren datubaseren bat aukeratu.
"Discretize" preprozesuko teknikarekin lan egingo dugu: Preprocess →
unsupervised → attributes. "Unsupervised" bezala ezagutzen da, klase (sailkatu-predizitu
nahi den) aldagaia erabiltzen ez duelako.
Diskretizazioa aplikatzeko: "Filter" → "Choose"
eta behin aukeratu eta gero, beltzez dagoen "Discretize" funtzioaren
izenaren gainean sakatuz gero: funtzio honen parametroak ikus daitezke eta
aldatu ("tune"). Informazio gehiago lor daiteke parametro bakoitzaren
inguruan "More" sakatuz. Behin parametroak "tuneatu" eta gero, "Apply"
sakatu funtzioa aplikatu izateko datuen gainean. Diskretizazioa aplikatu eta
gero eta bere efektua aldagaien balioen gainean ikusi eta gero, erantzun:
- zer dira "bins" eta "useEqualFrequency"
parametroak?
- zein da sortu den efektoa aldagaien
balioen gainean diskretizazioa aplikatzerakoan? zein "balio" ditu
orain aldagai bakoitzak (zer esan nahi dute "(23.5-26.4]" edo "(-inf-11.9]"
erako expresioek))?
- K-NN sailkatzaile baten asmatze tasa
berdina al da diskretizazioa aplikatuta edo aplikatu gabe? Zergatik?
[Galdera 6 -- Datu preprozesamendua
--- Balio galduen inputazioa] -- Weka-ren beste filtro erabilgarri bat "ReplaceMissingValues"
izenekoa da. Filtroen barruan, unsupervised --> attribute familian topa
dezakezu. Klikatu ezazu bere izenaren gainean eta irakurri zer sortzen duen
bere aplikazioak. Zergatik dago sartuta familia honetan? Kargatu ezazu goiko
loturan emandako "colic.arff"
datubasea. Galdutako zenbat balio agertzen dira aldagai bakoitzean? "ReplaceMissingValues"
filtroa aplikatzeak zer eragina du datubase honetan? Eragina berbera al da
aldagi nominal eta ordinaletan? Filtro hau aplikatuko ez bagenu, nola uste
duzu K-NN sailkatzaile batek kalkulatuko zituela distantziak aldagai batetan,
hau da, balio zehatz baten eta galdutako balio baten arteko distantzia
kalkulatzeko distance[A,?] (bota ezazu ideia bat)?
[Galdera 7 -- Recommender systems -- Social
bookmarking] --
Web 2.0-ren adibide onenetakoak bezala, "Collaborative filtering", "social
bookmarking" edo "Recommender systems" izeneko teknikak orain dela urte
gutxi agertu dira sekulako indarrez Adimen Artifiziala eta Data Analisian.
Ikus ezazu
"Recommender systems"-en definizioa Wikipedian, eta gehienbat teknika
hauek erabiltzen dituzten hainbat webguneen adibideak ("Examples"
atalean), batzuk
oso ezagunak: Amazon.com, last.fm, allposters.com,
StumbleUpon, eta abar.


"Recommender systems"-en lan egiteko forma K-NN
(auzokide hurbilena) sailkatzailearen lan egiteko formatik oso hurbil dago.
"Recommender systems"-ak saiatzen dira gure gusto eta preferentzi antzekoak
dituzten erabiltzaileak topatzen ("auzokideak"... hor dago K-NN-ren itzala),
guri proposatzeko hauei gustatu zaizkien (eta guk oraindik probatu ez dugun)
"aktibidade"-"adibideen" artetik, guk oraindik probatu-erosi
ez ditugunak.
Orain dela urte batzuk lehen plazaratu zen "recommender"
adibidea
pelikulena izan zen.
Pentsa dezagun erabiltzaile talde bat gaudela, eta
hauetako bakoitzak ikusi dituen pelikulei puntuazio-balorazio bat ematen
dio. Noski, denek ez dituzte ikusi pelikula guztiak. Eta denak gogoz daude
jakiteko ea ikusi ez dituzten pelikuletatik, zein izan daiteken gustatzea
litekeena. Eta "recommender system"-ek, erabiltzaileok karteleratik ikusi
ditugun pelikuleei emandako puntuazioetan oinarrituta, saiatzen dira "gure
gustu antzekoak dituzten erabiltzaileak topatzen bere erabiltzaileen datu
base handi horretan". Eta horrela, oraindik ikusi ez ditugun eta gure "gustoetan
antzeko diren erabiltzailei" gustatu zaizkien pelikulak gomendatuko dizkigu
sistemak automatikoki. Pelikulen "recommender systems" ezagunena mundu
mailan netflix.com da.
Egin beharrekoak:
- Jarritako loturaren
artikuluaren laburpena egin
- Komentatu itzazu galdera honetan jarri
dizkizuedan loturak-linkak.
- Zure iritzia eman: teknika hauek
erabilgarriak al dira? Erabiltzen al dituzu, bai zuk, edo zure
ingurukoek?
- Eman ezazu Internet-en dagoen beste
adibiderik "recommender systems" dena. Deskribatu ezazu. Pila daude...
- Beste alor batetan
erabilgarria izan daiteken "recommender system" baten ideia eman,
laburtuz bere ezaugarri nagusiak.
