====
WEKA
formatoko datubaseak: kurtso guztian zehar eta praktika guztietarako erabil
itzazu ====
[Galdera 1 -- Sailkatzaile anitzak WEKA-n:
the "meta" family of supervised classifiers] -- WEKA-ren "meta" familian
dauden hainbat "sailkatzaile anintzentzako": AdaBoostM1, Bagging,
Stacking eta Vote. Beraien "more" botoia sakatu behin aukeratu eta gero,
eta bakoitzarentzako, saiatu explikatzen ahal dituzun bere parametro
gehienak (denak ez dituzu ulertuko) (klaseko teoriarekin "matcheatu" WEKA-ren
terminologia).
[Galdera 2 -- Sailkatzaile anitzak: stacking
egitearen abantaila?] -- WEKA-k "meta" familiaren barruan sailkatzaile
anitzetarako aukera desberdinak eskeintzen ditu. Bertan ikusiko dituzu klase
teorikoetan aurkeztutako batzuk.
"Vote" saillkatzailearekin "gehiengoaren
botoaren" (edo "Plurality vote") sailkapen eskema egikaritzen da:
predizitutako klasea etiketatu gabeko kasu batentzat erabakitzen da
oinarrizko sailkatzaile talde baten botoaz. "Vote" metodoaren "classifiers"
parametroarekin oinarrizko sailkatzaile hauek hautatzen dituzu (naive Bayes,
J48, etc.). Ohartu zaitez, lehenik, "classifiers" parametro honetan
defektuzko "ZeroR" ("Zero Rules" = erregelarik ez = ez ikasi "ezer" eta
datu fitxategian klase nagusia beti predizitu edozein kasurentzat) sailkatzailea kendu behar
duzula...
"Stacking" eskemaz proposatutako
multisailkatzailea klase teorikoetan ikusi duzu. Bigarrengo nibel batetan
"meta"-sailkatzaile bat kokatzen da non hau entrenatua izaten den oinarrizko
sailkatzaileek (lehen nibela) predizitzen duten klaseekin (eta
bukaeran berriro klase erreala kokatuz: horrekin entrenatzen da bigarren nibeleko
metasailkatzailea, eta hauxe erabiliko da kasu bakoitzaren azken apostua
egiteko). Uler itzazu "classifiers" eta "metaClassifier" parametroak.
Uler ezazu klase teorikoetan ikusitakoa.
300 kasu baino gehiago dituen problema bat
aukeratu. Hiru zure hautazko sailkatzaileekin "Vote" eta "Stacking"
eskemak landu itzazu (azken honentzat bigarrengo nibelean "fidatzen" zaren
sailkatzaile bat kokatu), eta ikertuko dugu ea "Stacking"-en bigarrengo
nibel honek "plus" bat ematen digun. Zorizko hazi desberdinak ("More options"--
"random seed") erabiliz H metodoaren 5 exekuzioen bidez "Vote" eta "Stacking"
eskemen asmatze tasa estima ezazu: eta hauetan oinarrituz, pasatako
praktikan egin bezala, konparaketa estatistiko bat egin ezazu test ez-parametriko
baten bidez bi sailkatzaileen artean.
"Estatistikoki esangarria" al da "Stacking"-ek
ematen duen abantaila asmatze tasaren ikuspegitik? Oinarri estatistiko
batekin, hitzegin al daiteke sailkatzaile irabazle/galtzaile batetaz
konparaketan?
Gogoratu "statistical significance" (edo "p-value")
kontzeptuaren explikazio intuitiboak (pasatako Praktikaren 2. galderan):
- probabilitate bat da, 0 eta 1 artekoa.
Kontuz!!! SPSS-aren irteeran komaren ezkerrean "0"-a ez da agertzen.
Hobeto ulertzeko, probabilitate hori ehunekoetara pasa.
- "Esangarritasun asintotiko"-ak adierazten
digu konparatu ditugun bi zenbaki multzoek zenbateko "berdintasun-antzekotasun
maila" duten.
- "Esangarritasun asintotiko"-aren beste
definizio pixka bat zailagoa ondokoa da: konparatu ditugun bi zenbaki
multzoen artean dauden diferentziak esplikatzeko "azarrak"-"zoriak" duen
pisua.
- "Esangarritasun asintotiko" honen balio
%5-a baino txikiagoa bada, onartzen da konparatu ditugun bi
sailkatzaileen artean diferentzi handia ("esangarria") dagoela → orduan,
onartzen da H-metodoaren 5 exekuzioen asmatze tasen batazbesteko onena
duen sailkatzailea HOBEA DELA ESTATISTIKOKI, eta sailkatzaile IRABAZLE
batetaz hitzegin dezakegula.
- %5-eko muga hau estatistikaren muga
klasiko bat da, arbitrarioa ere bai. Baina "Esangarritasun asintotiko"-aren
maila %5-a baino handiagoa bada, ezin dezakegu hitzegin sailkatzaile
irabazle/galtzaile batetaz ("ezin gara busti").


[Galdera 3 -- Sailkapen gainbegiratua --
etiketatu gabeko kasu berri batentzat "apostua", iragarpena] -- Pentsa ezazu gure
datubaseko kasu guztiekin sailkatzaile bat eraiki dugula (kontutan hartu
sailkatzailea eraiki dugun kasu guztien klase etiketa jakin bat zutela).
Pentsa ezazu orain geroan kasu berri bat etortzen dela, baina KLASE GABEKOA,
ETIKETA GABEKOA (adibidez "Iris" problemaren kasuan 151 landarea non
botanikoak ez dakien zein iris motakoa den...). Ikasketa automatikoaren
funtzio nagusietako bat da aldez aurretik eraiki dugun sailkatzailearekin,
klaserik gabe etortzen diren kasu hauentzako klase aldagaia predizitzea, "apostua
egitea". Funtzio honi "kategorizatu" bezala ere ezagutzen zaio, edo
"class
prediction". Hemen sailkatzaileak "apostua" itxuan egiten du, eta benetan ez
daki asmatu duen edo ez: "spam karpetara joaten zaizkigu ere gure lagunen
mail-ak...", "edo euria iragarrita dagoenean biharko, gero eguzkia dugu..."
Goazen WEKA-n egoera hau simulatzea. Hautatu
lan egiteko WEKA formatoko datubase bat. Sortu ezazu *.arff fitxategi berri
bat zuk asmatutako 5 etiketatu gabeko kasuekin, non '?' balioa
jartzen duzun klasean (WEKA-k hau eskatzen du, "zerbait" jarri klase
aldagaian, nahiz balio galdua izan). Kontutan izan sortzen duzun fitxategi
berriak entrenamendukoaren formato bera jarraitu behar duena: inkluso bere "WEKA cabeceran",
aldagaien definizio berbera jarraituz: aprobetxatu entrenamendukoarena eta
kopiatu zuk asmatutako 5 klase gabeko instantzien fitxategian.
Begirada bat emaiozu hau egiteko WEKA-ren lan
manualari, eta "test-options"-eko bigarren aukeraren bidez ("supplied
test-set"), esandakoa simulatu daiteke. Eta ikusi zein klase predizitzen
duten zure aukerako diren bi sailkatzaile desberdinek, zuk asmatutako 5 kasuentzat.
Baina kontutan izan sailkatzaileak ez direla eraiki zure
5 instantziekin (klase gabekoak), baizik eta zure entrenamendu fitxategiko
guztiekin (hau da, "Preprocess" leihoan kargatu dituzun, eta etiketatutak
dauden kasu guztiekin...).
Lehenik kargatuta izan WEKA-n zure entrenamendu
fitxategia, klase erreala duten kasu guztietakoa: hauekin gerora predikzioak
egingo dituen sailkapen modeloa ikasiko da. Gero, WEKA-ri "Supplied
test-set" aukerarekin klase ezezaguneko kasuak eman behar dizkiozu.
Ikusteko
zein klase iragartzen den etiketarik ez duen kasu bakoitzarentzat, "More options"-en,
desaktibatuta dagoen aukera bat
aktibatu behar duzu. Zein?
Erakutsi zein den zure bi sailkatzaileek
iragartzen duten klasea zure 5 kasuko bakoitzarentzat. Ez diozu begiratu nahi "confusion
matrix"-i, non ez den diferenziatzen zer prediziten den kasu bakoitzarentzat,
baizik orokorrean. WEKA-ren irteeran hainbat kontzeptu agertzen dira klase
gabeko 5 kasu horietako bakoitzarentzat: "actual", "predicted", "error" (honek
ez du zentzurik), "probability distribution": laburki argitu eta komentatu
zer den hauetako bakoitza. ETA ULERTU EGITEN ARI ZARENA.
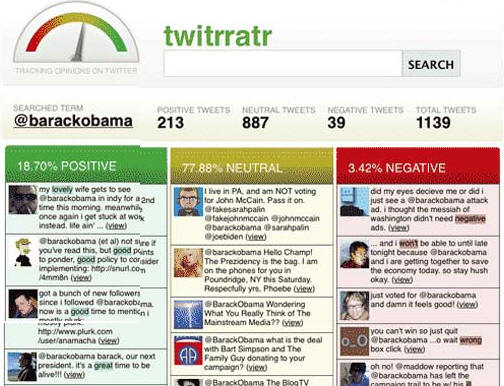
[Galdera 4 -- Sentiment Analysis -- Irakurketak] -- "Sentiment
Analysis" problema gure gizartean agertu berria da. Konpainia handiak (hotelak,
arropa eta diseinu markak...), beraiek mediotan erosten duten publizidadeaz
baino kezkatuagoak, Internet-eko foro eta blog-etan beraietaz nola
hitzegiten den eta zein imagina duten gehiago kezkatzen die, bait dakite
gaur egun foro horietara jotzen dugula eros dezakegun produktu bati buruz
kontsulta egiteko.
Nielsen, Asomo (Bilbon
dago hau), Jodange...
bezalako enpresak dedikatzen dira konpainia handiei informeak egitea
Internet-en duten imaginari buruz. Horrela, enpresa hauetako langileak ordu
asko dituzte Internet-en, baina ados egongo zareta nirekin ezin dutela
orduak eta orduak egon blog eta foro asko ikusten, eta hor dauden sarrerak
eta komentarioak irakurri eta "etiketatzen" eskuz (hau da, esanez
post batetan agertzen den imagina konpainia bati buruz positiboa den edo ez)... lan izugarria,
partzialki egin dezakete, baina "robot" edo "programa automatiko" bat behar
dute non, Internet "rastreatzen" duena konpainia edo produktu jakin baten
komentarioen inguruan, eta AUTOMATIKOKI kategorizatuko-sailkatuko duena post horietako
idazlearen sentimendua: "positive sentiment", "neutral sentiment","negative
sentiment" ("or opinion").
Irakur itzazu gai honen
inguruko bi artikulu hauek:
Irakurri eta gero, hurrengo galderei erantzun:
- iruditzen al zaizu mundu errealean aplikazio
honek erabilgarritasunik duenik? Zure iritzia eman problema honen geroari
buruz.
- antzematen al duzu "non dauden" datuak, hau
da, "nondik ateratzen-sortzen" diren datuak?
- zergatik da beharrezkoa "data mining" egitea,
datu analisia? ez al dago gizaki jakitunik non zihurtasun osoz klasifika
ditzaken kasu berriak?
- nondik joan daiteke "web mining" mundu hau?
Zein izan daiteke hurrengo aplikazioa, "the next frontier"?
- eta abar...

[Galdera 5 -- Aldagai aukeraketa -- Feature
selection -- Feature ranking -- Univariate feature selection] -- Zihur joan zarela somatzen kurtso
guztian zehar problema batetan, aldagai iragarle guztien garrantzia ez dela berdina klasea
predizitzerako garaian. Aldagai redundanteak (informazio bera aportatzen
dutenak: e.g., soldata eurotan eta soldata dolarretan) eta aldagai
garrantzigabekoak ("irrelevant features", klase-aldagaiarekin inongo
erlazioa ez dutenak) sailkatzailearen asmatze tasa gutxitzen dute. WEKA-rekin
aldagai aukeraketarako ariketa anitz egin daitezke bere "Select Attributes"
goiko fitxarekin ("pestaña"), eta era batera edo bestera jakin problema
baterako zeintzuk diren aldagai garrantzizkoenak. Arlo honi
"Feature selection"
bezala ezagutzen zaio eta oso erabilia da machine learning-en.
Erarik errazena jakiteko zeintzuk diren aldagai
garrantzizkoak, hauen ordenazio edo "ranking" bat egitean datza. "Ranking"
hauek isladatzen dute, handienetik txikira, zenbateko korrelazio maila (erlazioa)
duten problemaren aldagai iragarle bakoitzak klasearekin. Korrelazio maila
hauek kalkulatzeko metrika (neurri) asko daude teorian ("Attribute Evaluator",
WEKA-n). Hauetako hiru neurriek, zerikusi haundia dute sailkapen zuhaitzetan aldagaiak
kokatzeko neurriekin, hau da, entropia eta Informazio Teoriarekin: "gain
ratio", "info gain" (J48 eraikitzekoa) eta "symmetrical uncertainty".
Aukeratu itzazu eta beraien izenaren gainean klikatuz eta gero "More"
klikatuz ikusi zein formula erabiltzen duten aldagai prediktore baten
korrelazio maila kalkulatzeko eta hauek rankeatzeko: ulerterrazak dira.
Ohartu zaitez hauetakoak aukeratzerakoan, WEKA-k
esaten dizula soilik "Rankeatu" ditzakela eta ordenazio hori erakutsi.
Metrika hauek "univariate metric" dira, aldagaiak banan banan ikertzen
dituztelako, eta ez besteekin kontextu edo erlazioan.
10 aldagai iragarle baino gehiago dituen
datubase batentzat (hau da, "jokoa ematen" dizuna), ondokoa egin:
- "gain ratio", "info gain"
eta "symmetrical
uncertainty" metrika bakoitzarako erakutsi zein formula erabiltzen
duen aldagai-klase
arteko korrelazioa kalkulatzeko.
- metrika bakoitzarako eraiki ezazu dagokion
"ranking-a", aldagai iragarleen ordenazioa eraikitzen duena klasearekiko
duten korrelazio mailaren arabera. Aldagaien ezkerreko partean agertzen
den kantitatea korrelazio horren kalkuloa da. Hiru ranking-ak berdinak
al dira? Antzekoak? Analisi labur bat egin honen inguruan.
- ranking-aren goiko parteko aldagaiak omen
dira garrantzizkoenak erabilitako metrikaren arabera → "top-ranked
features": aldagai hauek J48-zuhaitz sailkatzailean "paper
garrantzizkoa" al dute (arbolaren goiko mailetan agertzen al dira)? Analisi labur bat egin honen inguruan.
- era honetako neurriek aldagai iragarleen
arteko redundantzia maila neurtzen al dute? Kapaz al dira detektatzeko,
adibidez "1st ranked and 3rd ranked" aldagai iragarleak redundanteak-antzekoak
direla, hau da, oso korrelatuak daudela beraien artean eta informazio
berbera ematen digutela problemaren klasearen inguruan (adibidez, gaurko
tenperatura Celsius edo Fahrenheit graduetan)? Bota ideiaren bat hau
ekiditeko...
[Galdera 6 -- Aldagai aukeraketa -- Feature
selection -- Feature ranking -- Univariate feature selection] -- Aurreko galderarekin
erlazionatuta. WEKA-ren lehenengo "Preprocess" fitxan posible da aldagaiak
ezabatzea modeloa egin baino lehen. Kontutan izan aurreko galderan egin
duzun ranking-a, eta "top-ranked"-eko portzio batekin geratu zaitez modeloak
eraikitzeko: zuk erabaki heren onenarekin, erdi onenarekin... (ez ezabatu
klase aldagaia!!!)
Test estatistiko ez-parametriko (gure kasuan,
"Mann Whitney" test) eta Hold-out asmatze-tasa
estimatzeko 5 exekuzioen bidez, konparaketa estatistiko bat egin ezazu ondoko bi eskemen
artean:
- 5-NN (5 bizilagun hurbilena) sailkatzaile baten bidez, non soilik
zuk erabaki duzun aldagai iragarle hobe rankeatuen portzio horrekin lan egingo
duena
- 5-NN sailkatzaile bat aldagai iragarle
original guztiekin
Ondokoa kontutan izan ezazu: "Ranker"
metodoaren parametroen artean, "numToSelect" parametroa erabilgarria da,
uler ezazu: exekuzioa egin eta gero, pantailaren ezker-behe parteko "Result-list"-en
propietateen artean (arratoiaren eskubiko botoiarekin) "Visualize reduced
data" erabilgarria al da? Zer erakusten dizu honek?
Abantailik ba
al du asmatze tasaren ikuspuntutik aldagai kopurua murriztea? Nahiz
eta aldagai iragarle kopurua murriztu, asmatze tasa ez al da "estatistikoki
txarragoa"? Era honetako konklusioak bildu eta komentatu.


 [Galdera
7 -- What did you discover about this subject? Where is your curiosity
leading you?] -- Zihur nago ez zara "ikasle funtzionarioen" artean
sentitzen, eta kuriosidadea, jakin-mina eta jakiteko gogoa hor daudela
bueltaka... pentsatu nahiko nuke aste hauetan zehar eta irakasgai honen
inguruan horrelako zerbait noizbait sentitu duzula. Horrela izan ez bada nik
ere zerbait gaizki egin dut.
[Galdera
7 -- What did you discover about this subject? Where is your curiosity
leading you?] -- Zihur nago ez zara "ikasle funtzionarioen" artean
sentitzen, eta kuriosidadea, jakin-mina eta jakiteko gogoa hor daudela
bueltaka... pentsatu nahiko nuke aste hauetan zehar eta irakasgai honen
inguruan horrelako zerbait noizbait sentitu duzula. Horrela izan ez bada nik
ere zerbait gaizki egin dut.
-
ikus ezazu "kdnuggets.com"
data-mining webguneko bisitariek zer esperientzia duten datu-analisien
gaineko hainbat iharduerei buruz. Egindako hainbat inkesten emaitzak
dira: egindako data-mining
aplikazioak, erabilitako data-mining
softwarea, analizatutako datuen eta datubasen
formatoa,
more data or better classification algorithm?, data-mining
algoritmoen
sinesgarritasun mailaren inguruan, analizatutako datubase
handiena... ------ zerbaitek ATENTZIOA DEITU AL DIZU? ZERK?
BESTE ZERBAIT ESPERO AL ZENUEN? Astero inkesta bat egiten dute webgune
honetan: egindako guztien zerrenda eta hauen emaitzak,
hemen.
-
pentsatu nahi dut hilabete
hauetan zehar webgune, aplikazio, software... interesanterik topatu
duzula datu analisiaren inguruan sarean. Zein? Laburtu bere helburuak?
Zergatik deitu dizu atentzioa? ...
[Galdera
8 -- Sailkapen ez gainbegiratua -- Clustering -- "Class discovery"] --
Ondoko
fitxategia ("food.arff"= clustering egiteko aproposa da. Bertan, hainbat
jaki-janari ("kasuak", datu analisiaren ikuspegitik) agertzen ditu, non
bakoitza karakterizatzen den hainbat aldagaiengatik: fitxategiaren testua
ikusiz gero, ilara-kasu bakoitzean, lehenik janari bakoitzaren izena
agertzen da, eta gero bera deskribatzen duten 5 aldagai (ulerterrazak, ez
da?). Kasuek ez dute "klase aldagairik":
-
helburua ez da kasu hauekin
sailkatzaile-modelo bat eraikitzea, etiketatu gabeko kasu berrien klasea
predizitzeko-iragartzeko (ikusi "Galdera 3"). "No class prediction". "There
is no class to be predicted".
-
ordea, helburua, kasu
hauetarako multzoak-clusterak sortzea da helburua" "class discovery",
non cluster bateko kasuek antzekotasun handia dute beraien artea, eta
cluster desberdinetakoek ordea antzekotasun oso txikia. Cluster hauek
sortu eta gero, oso tipikoa da multzo hauek "bataiatzea", cluster
horretan dauden kasuen ezaugarrietan oinarrituz: inkestak egin eta gero,
soziologoen "hobby" handia da hauxe.
Goazen "ariketa hau simulatzea"
eman dizuedan "food.arff" datubasearekin (baita janarien izena ingelesez
ikasteko aukera ona...):
-
WEKA-ren "cluster" pestaña hor
dago. Bertan, "SimpleKMeans" metodoa, clustering banatzailea egiteko.
Bere parametroetan klikatu eta gero "More": ez da espezifikatzen "Forgy"
edo "McQueen" metodoa den.
-
hainbat parametro ditu "SimpleKMeans"
metodoak: esplika itzazu ahal dituzunak, ulertzen dituzunak. Batzuk
ezinbestekoak dira clustering-a aurrera eramateko.
-
lan egiten hasi baino lehen,
cluster teknikak aplikatzeko, ez du zentzurik hauek aplikatzea "food.arff"-ren
"Name" (janariaren izena) string erako aldagaia erabiliz. Zergatik? Egindako
analisietatik ezaba ezazu, "Ignore Attributes" WEKA-ren botoia
erabiliz ("Cluster" pestañan). Cluster-ak egingo ditugu janari bakoitzaren elikagarritasun-ezaugarriekin:
proteinak, kaltzioa...
-
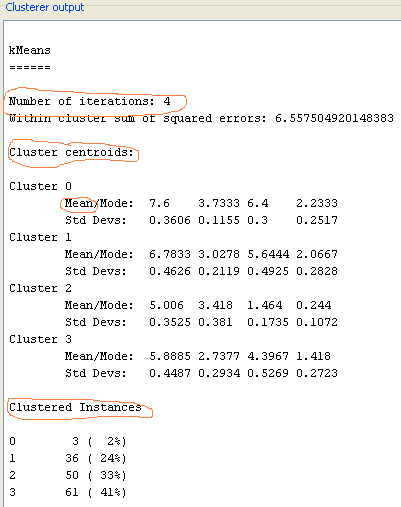
Cluster metodo baten
exekuzioak, era honetako "output"-ak sortzen ditu (orain dudan
WEKA-ren bertsioa ez da zehazki laborategietan duzutena, eta "output"-ak
ez dira guztiz berdinak: baina oso oso antzekoak, balioko zaizu...). "Food.arff" ez den
beste datubase batentzat egin dut. Esplika itzazu agertzen diren
kontzeptuak, zuk egindako "food.arff"-rentzako clustering-ean, eta klase
teorikoetako materiarekin erlazionatuz: number of iterations, cluster
centroids (zer adierazten dute mean/mode aldagai bakoitzarentzat? zenbat
zutabe daude "centroids"-etan? zerekin erlazionatzen da zutabe bakoitza?),
clustered instances.
-
Exekuzio bakoitzak WEKA-ren "Result-list"-en
(ezker aldean) emaitzaren hainbat propietate sortzen ditu: "right-click" eginez azken exekuzioan, emaitzaren "Visualize
cluster assignments" propietatea interesgarria da. "X ardatzean"
janariaren izena kokatu ("Name"), "Y ardatzean" nahi duzun beste
aldagaia, eta kolore bezala esleitutako cluster-a. Horrela ikus daiteke
zein cluster-etan multzoratu du janari bakoitza, eta cluster bakoitza
zein janari bereziekin osatuta dagoen. Proba ezazu hainbat cluster-multzo
kopuru desberdinekin, "eta gehien konbenzitzen" dizunarekin geratu:
emaidazu zergatiren bat justifikatzeko zure cluster kopuruaren aukera-konfigurazioa.
Ez da "automatikoa" izango, aurre-informaziorik
edo "intuiziorik" edo aditu bat izan gabe, jakitea ZENBAT CLUSTER-MULTZOtan
banatzea janari-elikagaiak. Teoria eta lan asko dago honen inguruan,
baina konklusio definitoborik ere ez. Ez dago neurri edo metrika zehatz
bat hori egiteko, batzutan intuizioa da onena, jakiteko zenbat cluster-etan
hobe den banatzea gure kasuak non: cluster bateko kasuek antzekotasun
handia dute beraien artea, eta cluster desberdinetakoek ordea
antzekotasun oso txikia. Hau da kriterio numerikoa: hala ere, ahal
denean "intuizioa" erabilia (hori eskatzen dizuet) ez da batzutan
aukerarik txarrena...
[Galdera
9 -- Sailkapen zuhaitzak -- "ad hoc" edo eskuz erabikitako arbolak] --
"Trees" familiaren barruan dagoen "UserClassifier" sailkatzaileak aukera
asko, eta oso kuriosoak, baditu. Beharbada lehenengo momentuan ez da erraza
berataz jabetzea, baina guztiz oinarrituta dago WEKA-ren erabiltzailearen
intuizioan: helburua delarik, zuk eskuz, 2-D-ko grafiketan oinarrituz, zure
sailkapen arbola eraiki dezazun. Zure atentzioa eraman ezazu lehenik
erakusten dizun 2-D grafikan ("Data Visualizer"): errektangeluen bidez
("Select instance ---> rectangle") defini ditzakezu arbolaren adarrak, eta hauen bidez bazoaz
pixkanaka zuk deritzozun arbola eraikitzen, definituz ingelesez deritzon "decision
boundaries" (klase desberdinen arteko "erabaki mugak").
Honetarako, beharbada "iris.arff" bezalako problema sinple bat erabiltzea da
onena (3 klase eta 4 aldagai iragarlekin).
Posible izango zen teknika hau erabiltzea datubase zailago batekin: aldagai
askotakoa, eta klase desberdinek beraien artean solapamendu handiagoa balute?
Saiatu zaitez sailkatzaile honen aukerak ulertzen. Komenta itzazu, eta
esaidazu zer iruditu zaizun. Eta definitu zein abantaila/desabantaila
ikusten dizkiozun.
Saiatu zaitez ulertzen zein lotura dagoen "Tree Visualizer" eta "Data
Visualizer", sailkatzaileak eskaintzen dituen bi leiho hauen artean:
antzemanez "Data Visualizer"-en delimitatzen dituzun "erabaki mugek", zein
eragina duten pixkanaka "Tree Visualizer"-en eraikitzen den sailkapen
zuhaitzaren estrukturan.
Ohartu zaitez eraikitze prozedura osoan zehar, WEKA-ren "txoria" mugitzen
dagoela, "model building"-ean murgilduta bait dago. Eta "Test-options"-en
aukera "10-fold cross-validation"-en baduzu, 11 aldiz egin araziko dizu
exekutatzea teknika osoa (11 aldiz pantaila guztiak): zergatik 11 aldiz (zein da
horietako bakoitza)? Modeloa balidatzea interesatzen al zaizu (hau da, bere
asmatze tasa kalkulatzea), edo soilik eraikitzea?
[Galdera
10 -- Aldagai aukeraketa -- wrapper teknikak -- Algoritmo genetikoak] -- Hasi
baino lehen, atera itzazu aldagai aukeraketarako apunteak, eta errepasatu:
bereziki "wrapper" (erderazko "envoltura" bezala itzuli daiteke). Erlazio estua du aurrez jarritako 5-6. galderekin. Lehenengo galdera osoa irakurri,
kontutan izan teoria, eta geor joan sekuentzian lantzen:
-
5. eta 6. galderetan
erabilitako "filter" teknikak, "univariate"
esaten zaie: aldagai iragarle bakoitzaren korrelazio maila neurtzen
zuten klasearekin, banan banan eta kontutan hartu gabe aldagai
iragarleen arteko erlazioak eta konplementagarritasuna. Ranking bat
osatzen zuten, non ranking horrek adierazten zuen aldagai iragarle
bakoitzak klasearekin duen korrelazio maila. Goazen gauzak pixka bat
hobeto egitea, "from UNIvariate to MULTIvariate data-analysis", kontutan
hartuz guk azkenean nahi duguna ALDAGAI AZPIMULTZO ON bat dela, eta ez
banan banan eta beraien artean kolaboratu gabe onak diren aldagaiak. "Wrapper"
teknikek aukera hau ematen digute.
-
"wrapper" aldagai
aukeraketarako teknika hauek, ALDAGAI AZPIMULTZO on bat aukeratzeko,
kontutan hartzen dute geroago erabiliko den sailkatzaile berezia.
-
aldagai azpimultzo hori
osatuta egongo zen problemaren klasearekin erlazio estua (korrelazio
altua) duten aldagai iragarletaz: baina era berean, beraien artean
aldagai iragarle hauek konplementagarriak izango ziren, eta ez ziren
adibidez redundanteak esango (hau da, informazio berbera emango
baziguten klaseari buruz; e.g., soldata eurotan edo soldata dolarretan).
-
horretarako, aldagai-azpimultzoen
espazioan "mugitu" behar dira, bilaketa heuristiko bat eginez.
-
horrela, bilaketa horretan
topatutako aldagai azpimultzo bakoitzarentzat, aldagai berezi horiekin
eraikiko zen sailkatzailearen asmatze tasa estimatzen dute: estimatutako
asmatze tasa honek gidatuko du bilaketa hori.
-
laborategietan aipatu dizuedan
bezala, ezin daiteke normalean bilaketa exaustibo bat egin,
garantizatzeko aldagai azpimultzo optimoa topatu dugula (hau da, aldagai
azpimultzo guztiak bisitatuz, estimatuz sailkatzaileen asmatze tasa
guztiak).
-
"d" aldagai iragarle dituen
problema batetarako, "2d" aldagai azpimultzo desberdin daude.
"d=20" denean, miloi bat baino gehiago aldagai iragarle azpimultzo daude:
guzti hauetarako sailkatzailearen asmatze tasa estimatzea ere, konputo
mendeak izango ziren makina askotarako. ULERTZEN AL DUZU HAU (aldagai
iragarle azpimultzoen kopuru hau)? JARRI ADIBIDE TXIKI BAT DEMOSTRATUZ
ULERTU DUZULA.
-
horrela, bilaketa heuristiko
bat egin behar da, aldagai-azpimultzoen espazioan, eta soluzio (aldagai
azpimultzo) suboptimo bat bueltatzearekin konformatu beharko gara.
-
bilaketa heuristiko hau egin
daiteke optimizazio eta adimen artifizialeko teknika heuristiko askoren
bitartez: ariketa honetan, ALGORITMO GENETIKOAK erabiliko ditugu
horretarako.
-
data-mining-en munduan
dabiltzan zientzilariek, askotan erabili izan dituzten algoritmo
genetikoak "feature subset selection" ("feature" == aldagai iragarle)
problemari aurre egiteko.
-
topa ezazu Internet-en lan
zientifikoren bat non algoritmo genetikoak erabiltzen dituen aldagai
azpimultzo on bat topatzeko: lan
horren "abstract"-a laburbildu ezazu.
-
WEKA-k ere aukera ematen digu
wrapper aldagai aukeraketa teknikak erabiltzeko aldagai azpimultzo on
bat topatzeko.
-
"Select Attributes" pestañan:
"Attribute evaluator" ---- "WrapperSubsetEval": bere parametroetan
klikatu ezazu, eta hiru lehenengoak ("classifier", "fold", "seed")
ulertu, eta explika itzazu.
-
ariketa lantzeko,
ACB-ko saskibaloiko datubasea eta naive-Bayes edo 5-NN
sailkatzailearekin lan egin.
Nola estimatuko duzu aldagai azpimultzo bakoitzaren asmatze tasa (zein
teknikaren bidez)?
-
zergatik proposatzen
dizuet naive-Bayes edo 5-NN bezalako sailkatzaile sinple bat, eta ez
sailkatzaile konplexuago bat wrapper bilaketarako?
-
"Select Attributes"
pestañan, bilaketa egiteko aldagai-azpimultzoen espazioan, optimizazioko
eta adimen artifizialeko teknika heuristiko anitz daude: ZEINTZUK
EZAGUTZEN DITUZU?
-
horien artean,
algoritmo genetikoak
daude: AUKERATU, ETA BERE LEHENENGO LAU PARAMETROAK ESPLIKATU, klaseko
teoriarekin hestuki erlazionatuz: "crossoverProb", "maxGenerations", "mutationProb",
"populationSize".
-
[KONTUZ: WEKA-k, bilaketak
egiterakoan, aldagai azpimultzo baten asmatze tasaren estimazioa "MERIT"
terminoarekin isladatzen du, non aldagai azpimultzoaren ERRORE TASA
ESTIMATUA isladatzen duen: errorea, hau da, orain arte erabilitako
asmatze tasaren konplementarioa]. Saiatu ulertzen WEKA-ren emaitzako
informazio gehiena. Algoritmo genetikoetarako informazio anitz dago: "merit",
aukeratutako aldagaiak, eta abar.
-
proba informalak egin itzazu algoritmo
genetikoekin, eta beste bi bilaketa heuristiko teknikekin (ulertzen
dituzunak: lehenengo bere parametroak ikusi eta ulertu).
-
ERANTZUN:
-
zein bilaketa teknikak
aukeratu dituzu?
-
zer balio eman diezu
bilaketa tekniko hauen parametroei (algoritmo genetikoak barne)? [kontuz
"RandomSearch"-en "SearchPercent" parametroarekin]
-
zein teknikak eman dizkizu
emaitzarik onenak? (test-estatistiko bat egin beharko genuke hau
sendo zihurtatzeko, baina informalki egingo dugu)
-
egindako proba guzti
hauetan, "bukatu ezinda" geratu al zaizu WEKA-ren txoritxoa probaren
batetan? zein proban, zein bilaketa heuristiko eta parametro
balioekin?
LABORATEGIEKIN BUKATZEKO, zuen
IRITZI PERTSONALA jaso nahiko nuke:
-
zer aldatuko zenuke
laborategien planteamendutik?
-
zer da gehien gustatu
dizuena laborategi eta jarritako galderetatik?
-
galderak nola planteatzen
ditudan erarekin gustora al zaudete?
-
zer egin nezaken, irakasle
bezala eta zuei behartu gabe, bolondresko laborategietara gehiago
etortzeko?
-
kuriosidadea piztu al dizue,
nahiz gutxi, era batera edo bestera, irakasgaiak?
-
eta abar... nahi duzun
edozien irakokizun, eskerrikasko.