[Galdera 15 -- Galdera hau
apirilak 2-ko laborategian burutu behar da
-- Zortzigarran gaia: Sailkapen ez gainbegiratua -- Clustering
banatzailea -- "Class discovery"]
Errepasatu
"sailkapen ez-gainbegiratuko" gardenkiak: bereziki, clustering banatzailea.
Ondoko
fitxategia ("food.arff")
clustering (sailkapen
ez gainbegiratua) egiteko aproposa da. Bertan, hainbat
jaki-janari ("kasuak") agertzen ditu, non
bakoitza karakterizatzen den bost aldagaiengatik: proteina kopurua,
kaltzioa... Fitxategiaren testua
ikusiz gero, ilara-kasu bakoitzean, lehenik janari bakoitzaren izena
agertzen da, eta gero bera deskribatzen duten 5 aldagai (ulerterrazak, ez
da?).
Haragia oinarritzat duten janari plater-janari batzuk daude; besteak, arraia
oinarritzat dutenak.
Datubase aproposa da ingelesa praktikatzeko, jakien inguruan.
Kasuek ez dute "klase aldagairik":
helburua ez da kasu hauekin sailkatzaile-modelo bat eraikitzea, ez da sailkapen gainbegiratura berbideratua dagoen problema, ez etiketatu gabeko kasu berrien klasea predizitzeko-iragartzeko. "No class prediction". "There is no class to be predicted".
ordea, helburua, kasu hauetarako multzoak-clusterak sortzea da helburua, "class discovery": non cluster bateko kasuek antzekotasun handia dute beraien artean, eta cluster desberdinetakoek ordea antzekotasun txikia. Cluster hauek sortu eta gero, oso tipikoa da, domeinuan aditua den pertsona batekin, multzo hauek "bataiatzea" eta aztertzea zer kasu tipo dauden cluster bakoitzean, cluster horretan dauden kasuen ezaugarrietan oinarrituz: inkestak egin eta gero, soziologoen "hobby" handia da hauxe.
Goazen "ariketa hau simulatzea" eman dizuedan "food.arff" datubasearekin, clustering banatzailearen bidez:
WEKA-ren "cluster" leihoa-pestaña hor dago. Bertan, "SimpleKMeans" metodoa, clustering banatzailea egiteko. Bere parametroetan klikatu eta gero, "More" botoiak esplikatuko dizkizu.
hainbat parametro ditu "SimpleKMeans" metodoak ("click" egin beltzez dagoen metodoaren izenean): esplika itzazu laburki "maxIterations", "distanceFunction", "numClusters".
lan egiten hasi baino lehen, cluster teknikak aplikatzeko, ez du zentzurik hauek aplikatzea "food.arff"-ren "Name" (janariaren izena) string erako aldagaia erabiliz. Egindako analisietatik ezaba ezazu, "Ignore Attributes" WEKA-ren botoia erabiliz ("Cluster" leihoa). Cluster-ak egingo ditugu janari bakoitzaren elikagarritasun-ezaugarriekin soilik (ez "name" string-arekin): proteinak, kaltzioa...
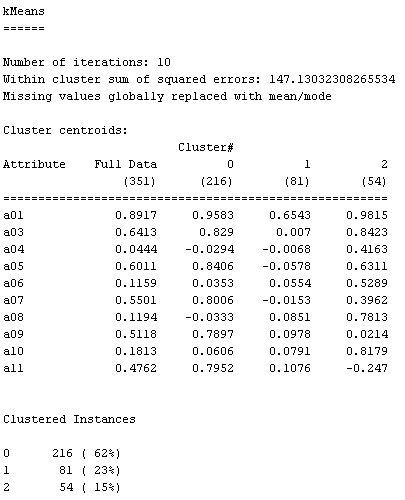
Cluster metodo baten
exekuzioak, era honetako "output"-ak sortzen ditu, ikus beheko
irudia (WEKA-ren "pantallazoa"). "Food.arff" ez den
beste datubase batentzat egin dut.
Esplika itzazu agertzen diren
kontzeptuak, zuk egindako "food.arff"-rentzako clustering-ean, eta klase
teorikoetako materiarekin erlazionatuz: number of iterations, cluster
centroids, full data, clustered instances.
Zenbat
zutabe daude "centroids"-etan? Zerekin du erlazioa "centroids"-eko
zutabe bakoitzak?
Exekuzio bakoitzak WEKA-ren "Result-list"-en (ezker aldean) emaitzaren hainbat propietate sortzen ditu: "right-click" eginez azken exekuzioan, emaitzaren "Visualize cluster assignments" propietatea interesgarria da.
"X ardatzean"
janariaren izena kokatu ("Name"), eta horrela ikus daiteke
zein cluster-etan multzoratu duen janari bakoitza; eta cluster bakoitza
zein janari bereziekin osatuta dagoen. Koloreak erabiltzen ditu WEKA-k
cluster-ak adierazteko.
"X" ardatzen kokatutako janari bakoitza zein den identifikatzeko, soilik
janariaren izenaren ("Name") lehenengo letrak agertzen dira: zein janari
den identifikatzeko trukotxo bat izan daiteke, WEKA-ren lehen leihoko "Preprocess-->Edit"
egitea, horrela leiho banandu batetan kasuak, datu matrizea osoki
ikustea eta "Name" ikustea. Ez da oso "GUI" ("graphical
interface") erakargarria, baina tira...
"X" eta "Y" ardatzetan beste bi edozein aldagai kokatuz gero (e.g. "Fat" eta "Calcium"), eta koloreak erabiliz cluster-a adierazteko, janari eta cluster desberdinak nola kokatzen diren 2-D grafika horretan ikus daiteke.
Ohartu zaitez non grafika
horretan, kasuetan klikatuz, kasuari buruzko informazioa agertzen dela
leiho batetan: kasuaren aldagai guztien balioa.
Proba ezazu hainbat cluster-multzo kopuru desberdinekin (2 edo 3, gehienez), "eta gehien konbenzitzen" dizunarekin geratu. Lortutako cluster-en ebaluzaio kualitatiboa:
haragia oinarritzat duten kasu-janari guztiak cluster berberean sartu
al ditu? Kontutan izan kasuak (elikagaiak) multzokatu dituela
beraien ezaugarri dietetikoen arabera (calcium, protein...), eta ez
haragia edo arraina diren arabera (hori soilik zuk dakizu). Cluster-multzo berdinean arrai eta haragia oinarritzat duten janaririk al daude?
Bere cluster-eko "centroide"-tik "urrun" dagoen kasurik al dago, hau da,
"outlier" antzekorik?... era honetako galderek lagunduko dizute ulertzeko egindakoa, eta
sorpresarik dagoen espero zitekeenarekin konparatuz. Probatzen joan
beharko zara grafika desberdinak, aldagaiak aldatuz.
Ez da "automatikoa" izango, aurre-informaziorik
edo "intuiziorik" edo aditu bat izan gabe, jakitea zenbat
clusteretan ("number of clusters") banatzea janari-elikagaiak. Teoria eta lan asko dago honen inguruan,
baina konklusio definitiborik ere ez. Ez dago neurri edo metrika zehatz
bat hori aurre-erabakitzeko, batzutan intuizioa da onena, jakiteko zenbat cluster-etan
hobe den banatzea gure kasuak non: cluster bateko kasuek antzekotasun
handia dute beraien artean (aldagaien balioen arabera), eta cluster desberdinetakoek ordea
antzekotasun oso txikia. Hau da kriterio numerikoa: hala ere, ahal
denean "intuizioa" erabiltzea (hori eskatzen dizuet) ez da batzutan
aukerarik txarrena...
WEKA-ren azken bertsioak
badu "clustering hierarkiko" metodo bat. Probatzen egon naiz ordea eta
dendogramak ez dira ondo irudikatzen...
Ondoko
loturan eskeintzen den "demoa" landuagoa dago: "X" ardatzeko balioa
soilik hartzen du aldagaitzat puntuak (kasuak) "clusterizatzeko", pausuz
pausu ("Step") bi kasu hurbilenak lotuz dendograma eratuz. Ulertuko
duzulakoan nago, bestela galdetu bildurrik gabe.