KONPUTAZIO-ZIENTZIEN
METODO MATEMATIKOAK 12-13 (KZMM)
UNIVERSIDAD DEL PAIS VASCO - EUSKAL HERRIKO
UNIBERTSITATEA, UPV-EHU

LAN PRAKTIKOAK -- ENUNTZIATUAK
Webgune hau galderekin zabaltzen joango da kurtsoa aurrera joan ahala
===== Joan zaitezte laborategietan nik esandago galderak egiten OpenOffice edo
Word dokumentu batetan. Zein galdera entregatu behar diren moodle bidez eta noiz,
aipatuko dut webgune honen edo moodle bitartez: esan bezala, epe hauek zuen
inplikazioaren arabera jarriko ditut
[Galdera
16 -- Sailkapen gainbegiratua -- Klaserik gabeko kasu berrien klasea
iragarri -- "Class prediction"]
Nere ustez, egitera goazen ariketa hau, sailkapenaren oinarrietako bat da: hau da,
klasea ezaguna dugun kasu etiketatuekin sailkatzaile bat eraiki, eta ikasitako
sailkatzaile honen bidez, klase ezezaguna duten kasu berrien klasea iragarri,
predizitu, "class prediction". Honi ere, ingelesez, "categorize" ere deitzen zaio.
Lehenik, ulertu, iragarpen hau, klasea ezezaguna den kasuen gainean, "apostu" bat dela, "bet": hau da, sailkatzaileak
ez daki asmatu duen ala ez iragarritakoarekin. Hala ere, hor ditugu estimatutako
asmatze tasak eta errore matrizea ausnartzeko zenbateko doitasuna izan dezaken
gure sailkapenak: gogoratu asmatze tasa hori etiketatutako kasuekin estimatu
dela. Noski, ezin ditugu erabili klasea ezezaguna duten kasuak asmatze tasarik
estimatzeko, ez bait dakigu ondo iragarri dugun edo ez...
Goazen WEKA-n egoera hau simulatzea bi sailkatzaile desberdinekin. Hautatu
lan egiteko WEKA formatoko datubase bat (zuk nahi duzuna: pasatako asteko
ariketan bi datubase "fitxatu" zenituen: horietako bat), non orain arte bezala, kasu guztiak
etiketatutak dituen (hau da, klase ezagunekoak diren).
"Preprocess" leihoan kargatuta izan: hauekin eraikiko da sailkatzailea.
Eta etiketatutako kasu hauekin ikasten den modeloa erabiliko da, gerora
datozten kasu berrien (eta klase ezezaguna duten) klasea iragartzeko.
Sortu ezazu WEKA-ren *.arff fitxategi berri
bat ZUK ASMATUTAKO 5 etiketatu gabeko kasuekin, non '?' balioa
jartzen duzun klasean (WEKA-k hau eskatzen du, "zerbait" jarri klase
aldagaian, nahiz balio galdua izan): "unlabeled, unseen samples". Kontutan izan sortzen duzun fitxategi
berriak entrenamendukoaren formato bera jarraitu behar duela: inkluso bere "WEKA cabeceran",
aldagaien definizio berbera jarraituz: aprobetxatu entrenamendukoaren
"cabecera",
kopiatuz zuk asmatutako 5 klase gabeko instantzien fitxategian.
Bigarren fitxategi hau, etiketatu gabekoa, "Classify"
leihoko "test-options"-eko bigarren aukeraren bidez ("supplied
test-set") kargatu. Eta ikusi zein klase predizitzen
duten naive-Bayes eta 5-NN (5 bizilagun hurbilenak) sailkatzaileek, zuk asmatutako 5 kasuko
bakoitzarentzat. Baina kontutan izan sailkatzaileak ez direla eraiki zure
5 instantziekin (klase gabekoak, hauekin ezin da gainbegiratutako
sailkatzailerik ikasi), baizik eta zure entrenamendu fitxategiko
guztiekin (hau da, "Preprocess" leihoan kargatu dituzun, eta etiketatutak
dauden kasu guztiekin...).
Ikusteko
zein klase iragartzen den etiketarik ez duen kasu bakoitzarentzat, "More options"-en,
desaktibatuta dagoen "Output Predictions" aukera aktibatu.
Erakutsi zein den zure bi sailkatzaileek
iragartzen duten klasea zure 5 kasuko bakoitzarentzat. Ez diozu begiratu
behar "confusion
matrix"-i, non ez den desberdintzen zer iragartzen den kasu indibidual bakoitzarentzat.
WEKA-ren irteeran hainbat kontzeptu agertzen dira klase
gabeko 5 kasu horietako bakoitzarentzat, eta hor informazio asko dugu
iragarritako klasearen inguruan 5 kasu hauetako bakoitzarentzat: "actual", "predicted", "error" (honek
ez du zentzurik), "probability distribution": laburki argitu eta komentatu
zer den hauetako bakoitza, bereziki "probability distribution" (zenbat
zutabe ditu "probability distribution"-ek? Klase aldagaiaren balio adina,
ez da?).
Ausnartzeko: 5-NN sailkatzailearen kasuan, nola atera ditu klasearen balio
bakoitzeko "probability" horiek?
[Galdera 17 -- Data mining orokorrean]
Kurtsoa jadanik aurrera doa, eta hasieran sorpresa bat
izan ziteken disziplina ("data analisiaren" rol-a gure gizartean), jadanik ez
da.
Gustatuko litzaidake jakitea irakasgaiarekin hasi eta asteak aurrera joan ahala,
zure inguran antzeman izan dituzula non dauden, non egon daitezken datu
analisiaren hainbat aplikazio.
Horrela, Internet-en topatu duzun eta datu
analisiarekin zerikusi hestua duen webgune bat erakutsidazu, eta komentatu eta
deskribatu:
-
Zein datu analisi aplikazioa
deskribatzen du?
-
Zehaztu: zer da sailkatu nahi den
gertaera (gure klase aldagaia)? Hau iragartzeko zeintzuk dira aldagai
iragarleak (laburbilduz)?
-
"Ez jakintasuna" ("uncertainty")
al dago eremu horretan, hau da, ez al dago giza aditurik zehazki, beti eta
azkartasunez iragarri nahi duguna emango diguna?
-
Zein enpresa/taldek plazaratzen du
aplikazioa? Zein interesekin, zein etekin espero du?
-
Beste zure komentarioetara irekita...
[Galdera 15 -- Galdera hau
apirilak 25-ko laborategian burutu behar da -- Algoritmo genetikoak]
Laborategia hasteko, algoritmo genetikoen gaiko
gardenkiak errepasatu.
Beharbada salto handia somatu dugu
ikasketa automatikoko gaietatik, algoritmo genetikoen gaira pasatzerakoan.
Jadanik ez gaude datu analisia egiten, baizik eta "optimizazioa": baina
algoritmo genetikoak adimen artifizialeko teknikarik erabilienetakoa da gaur
egun industrian eta akademian. Eta horregatik erakutsi nahi dizkizuegu.
Algoritmo genetikoak, adimen artifizialeko beste
bilaketa heuristikoak
bezala (adibidez, branch and bound, aurrerako edo atzerako bileketak,
txingurri
koloniak...), optimizazio problemak era suboptimo batetan ebazteko algoritmo
efizienteak dira.
"Optimizazioa" edo "Ikerkuntza Eragilea" irakasgaiaetan
erakusten den "Simplex" algoritmoak ebatzi ezin ditzakeen problemetarako, hor
daude adibidez algoritmo genetikoak.
Hauetako problema bat, ikasketa
automatikoko problema batean aldagai iragarleen azpimultzo optimoa aukeratzea
da. Beste problema klasiko bat,
bidaiariaren problema (TSP, Traveling Salesman Problem) da: "n" hiri behin bisitatzeko distantzia minimizatu.
Problema hau on-line ebazten duen aplikazio grafikoa
hemen ikus dezakezu: hiriak 2-D batetan zuk kokatu ditzakezu, gurutzaketa
eta mutazio eragiketa motak ere bai; printzipioz, populazioko 16 soluzio-indibiduo
guztiak ikus ditzakezu nola eboluzionatzen duten, eta "Change view" klikatuz
unerarteko soluziorik onena ikus dezakezu.
Bestetik,
diseinu-optimizazio problema anitz algoritmo genetikoen bidez ebazten dira:
goazen laborategia ondoko
"hegazkin baten diseinua optimizatzeko" algoritmo genetikoak erabiltzen
dituen lana ikuskatzea, gainetik ikusiz zeintzuk diren optimizatu nahi diren
aldagaiak eta diseinu-problema: azkenean, string batetan errepresentatu nahi
dira hegazkin baten diseinuko aldagai eta arlo guztiak. Eta string horren balio
optimoa bilatu nahi dugu, gure kasuan algoritmo genetikoen bidez optimizatuz.
Era honetako diseinu problemetan,
arazoa dago askotan proposatzen den diseinu-soluzio baten egokitzapen
funtzioa kalkulatzen: hau da, zein ona edo txarra den proposatutako soluzio hori
(hau da, bilaketan zehar topatutako soluzio hori).
Bidaiariaren probleman analitikoki kalkulatu daiteke (hiri pareen arteko
distantziak batutzen, hauek bait dakizkigu): baina diseinu problema askotan, "simulazioaren"
bidez egiten da egokitzapen funtzioaren kalkuloa. Ikus adibidez 2 gurpil-urdin eta bi goi-borobil-gorri dituen
kotxe honen diseinuaren simulazioa:
algoritmo genetikoen bidez sortzen eta optimizatzen ditu soluzioak, ondo fijatu.
Proposatzen duen kotxe-diseinu baten egokitzapen funtzioa: ibiltzen duen
distantzia, goi-borobil-gorriak bolkatu eta zorua ikutu gabe.
Ondoko beste hiru adibideak ikusi, eta
ulertu optimizatu nahi den diseinu-problema:
SOFTWARE BATEKIN
PROBAK ETA TESTAK:
Ariketa honetan
goazen bilaketarako heuristikoentzako
LiO ( "Librería
de Investigación Operativa") izeneko libreriara hurbiltzea. Software libreri hau
Castilla - La Manchako "Sistemas Inteligentes y Minería de Datos" ikerkuntza
taldean garatu da, eta askok deitzen diote "bilaketarako heuristikoen WEKA".
Libreria polita da ikusteko bilaketarako heuristikoek ere "funtzionatzen dutela",
eta praktikara pasatzeko teoriatik. WEKA bezala, soilik Java runtime behar da
zuen ordenagailuan exekutatzeko (fakultateko C:\LiO\deploy karpetan dago, edo
ondoko
loturan jetsi nahi izanez gero):
PROMPT>>> java
-jar LiO.jar
LiO-ren interfaz-ak lau lan-eremu
(panel) nagusi ditu, eta hauetako bakoitza konfiguratu daiteke
("Configure"):
-
optimizatu eta ebatzi nahi
den problema ("task");
-
problema ebazteko erabili
nahi den algoritmo edo heuristikoa ("search algorithm");
-
algoritmoa gelditzeko
kriterio edo irizpidea ("stop condition");
-
bilaketaren exekuzioaren
emaitzari buruz jaso nahi dugun informazio kopurua ("search
output": aktibatu ezazu
defektuz desaktibatuta dagoen "showBestIndividual" aukera).
Laborategia ilustratzeko eta
zuei LiO softwareari sarrera egiteko, ondoko problemarekin jolastuko dugu:
OneMax
problem (LiO-n: Task-->bitchain), hau da, bere balioak
bitarrak (1 edo 0) izan daiteken string baten balioak batu, hau da, "tonteria
bat", "Bit Counting" ere deitzen zaio: optimoa (1,1,1,...1,1) string-a (soluzioa) da, baina
optimizatzen gaudenean hori algoritmoak ez daki. Funtzio hau optimizatzeko
ez genuke inoiz algoritmo genetiko bat erabiliko: bere funtzio zehatza
dakigunez, bere soluzio
optimoa ezaguna da aldez aurretik. Ordea, erabiltzen dira era honetako
funtzioak testatzeko
ea zenbateko doitasuna duten algoritmo genetikoek, eta beste bilaketa
heuristikoek, beraien optimora hurbiltzeko.
LiO-ri buruzko hainbat
informazio:
-
Eskubiko "Results"
leihoan ikusi algoritmoaren exekuzioaren emaitzen informazio nagusia.
-
Emaitzaren balio
nagusia, "Best fitness" da; hau da, egindako bilaketan topatutako
Egokitzapen Funtzio oneneko soluzioaren egokitzapen balioa.
-
"Search output"
--> "Show best
individual": aktibatu ezazu defektuz desaktibatuta dagoen aukera hau
, bilaketa guztian topatutako "fitness" oneneko soluzioa erakusteko, [X1,
X2...Xsize], bere aldagai guztien balioa: "OneMax"-en
ikus dezakezu non ez duen 1-ekoa topatu...
-
"Search Algorithm": ikusi zenbat bilaketa heuristiko dauden... honegatik deitzen zaio "bilaketa
heuristikoen WEKA".
-
"Search Algortihm"-->
"Configure": aukeratutako algoritmoaren parametroak ikusi. Aukeratu
ere "genetic--> StandardGeneticAlgorithm", eta hori egin eta gero
"Configure" botoia sakatuz, ikusi nola alda ditzakezun algoritmo
genetikoaren parametroen balioak: gurutzaketa eta mutazio
probabilitateak, populazio tamaina...
-
"Task"-->
"Configure"--> "Size": aldagai kopurua, problemaren Xi
kopurua, dimentsioa. OneMax funtzioaren kasuan, string-aren tamaina,
aldagai bitar kopurua. Defektuz, "OneMax"-entzat, 100 bit-aldagai.
-
MAX / MIN: kontutan izan
LiO-k beti "maximizatze forman" lan egiten duela. Horrela, TSP minimizatze forman denez, kontutan izan LiO-k
max(z) ≈ min(-z) aplikatzen duela eta TSP helburu funtzioaren (egindako kilometro
kopurua) negatiboarekin lan egiten duela. Kontutan izan maximizatzea
funtzio bat (max(z)) edo minimizatzea bere negatiboa (min(-z))
soluzio berbera dutela (x*). Kontuz, maximizatzen denean, -21 da -27
baino hobea...
-
"Stop condition": LiO-k,
bilaketa geratzeko 5 irizpide ditu, uler itzazu: horietako bakar bat betetzearekin,
algoritmoa gelditzen da. Nere gomendioa da irizpide hauekin "jolastea"
eta luzatzea ("0 gehiago jarri eskubian irizpide bakoitzari...")
-
Behin "Run"
zanpatu eta gero eta gelditu arte, bilaketaren martxari buruzko
informazioa ikus daiteke "Show Progress" botoiaz (horretarako,
motz ez geratzeko, lehenengo .
-
Algoritmo
genetiko baten bi exekuzio desberdinek emaitza berdina eman behar al dute?
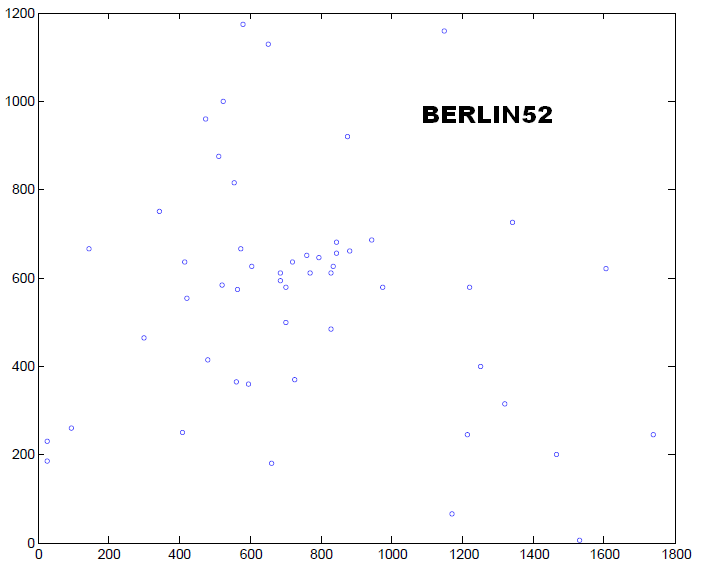
Orain, zuretzako: bidaiariaren
problemarekin arituko zara, TSP problemaren "Berlin52" (LiO-ren
panelean: Task-->permutation-->
SymmetricTSP) bezala ezagutzen den problema, non Berlin inguruko 52
puntu (koordenatuak ikusi
hemen) ahalik eta distantzia minimoa erabilita behin bisitatu nahi
diren. Beheko irudiak puntu horiek adierazten ditu.
Problema honetarako ondokoa egin, laburbildu ikusitakoa eta jasotako
emaitzak:
-
Gurutzaketa probabilitate
altua (1-tik hurbil) edo baxua (0.5.tik hurbil). Zein hobe?
Exekuzio bat baino gehiago egin beharko duzu
algoritmo eta parametroen balio berberekin, ez da...? Gutxienez 3
exekuzioetan oinarritu, "Best fitness" balioaren batazbestekoa
kalkulatuz eta batazbesteko honekin ondorioak ateraz.
-
Mutazio probabilitate
altua (0.8-tik hurbil) edo baxua (0-tik hurbil). Zein hobe?..
-
Populazio tamaina altua
edo baxua. Zein hobe?
-
Zein hiru parametroen (gurutzaketa
eta mutazio probabilitateak, populazio tamaina) konbinaketa-balioa
gomendatuko zenuke? Probatu ere konbinaketa balio hori.
[Galdera 14 -- Galdera hau
apirilak 8-ko laborategian burutu behar da -- Sailkapen ez-gainbegiratua, "clustering",
"class discovery"]
Laborategia hasteko, klase teorikoetako
"clustering - sailkapen ez gainbegiratu" gaiko
gardenkiak errepasatu, 10 minutu erabiliz, gai interesgarria da:
clustering banatzailea eta clustering hierarkikoa, bereziki.
Ondoko
fitxategia ("food.arff")
clustering (sailkapen
ez gainbegiratua) egiteko aproposa da.
Bertan, hainbat
jaki-janari ("kasuak", datu analisiaren ikuspegitik) agertzen ditu, non
bakoitza karakterizatzen den hainbat aldagaiengatik: proteina kopurua,
kaltzioa... Fitxategiaren testua
ikusiz gero, ilara-kasu bakoitzean, lehenik janari bakoitzaren izena
agertzen da ("name"), eta gero bera deskribatzen duten 5 aldagai (ulerterrazak, ez
da?).
Haragia oinarritzat duten janari plater-janari batzuk daude; besteak, arraia
oinarritzat dutenak.
Datubase aproposa da ingelesa praktikatzeko, jakien inguruan.
Kasuek ez dute "klase aldagairik" (ez dago WEKA-n kolorerik...),
hau da:
-
helburua ez da kasu hauekin
sailkatzaile-modelo bat eraikitzea, ez da sailkapen gainbegiratura
berbideratua dagoen problema, ez etiketatu gabeko kasu berrien klasea
predizitzeko-iragartzeko. "No class prediction". "There
is no class to be predicted".
-
ordea, helburua, kasu
hauetarako multzoak-clusterak sortzea da helburua" "class discovery",
non cluster bateko kasuek antzekotasun handia dute beraien artea, eta
cluster desberdinetakoek ordea antzekotasun txikia. Cluster hauek
sortu eta gero, oso tipikoa da, domeinuan aditua den pertsona batekin, multzo hauek "bataiatzea" eta
aztertzea zer kasu tipo dauden cluster bakoitzean, cluster horretan dauden kasuen ezaugarrietan oinarrituz: inkestak egin eta gero,
soziologoen "hobby" handia da hauxe.
-
hau ulertzea ezinbestekoa da,
hau da, "sailkapen gainbegiratuko" modelorik eraikitzea datu hauen
gainean zentzurik ez duela; bestetik, aproposa da "clustering" teknikak
aplikatzeko.
Goazen "ariketa hau simulatzea"
proposatu dizuedan "food.arff" datubasearekin,
clustering banatzailearen bidez:
-
WEKA-ren "cluster" leihoa
("pestaña") hor
dago. Bertan, "SimpleKMeans" metodoa, clustering banatzailea egiteko.
Bere parametroetan klikatu eta gero, "More" botoiak
esplikatuko dizkizu.
-
hainbat parametro ditu "SimpleKMeans"
metodoak ("click" egin beltzez dagoen metodoaren izenean): esplika itzazu
laburki "maxIterations", "distanceFunction", "numClusters".
-
lan egiten hasi baino lehen,
cluster teknikak aplikatzeko, ez du zentzurik hauek aplikatzea "food.arff"-ren
"Name" (janariaren izena) string erako aldagaia erabiliz. Egindako
analisietatik ezaba ezazu, "Ignore Attributes" WEKA-ren botoia
erabiliz ("Cluster" leihoan). Cluster-ak egingo ditugu janari bakoitzaren elikagarritasun-ezaugarriekin,
soilik (ez "name" string-arekin):
proteinak, kaltzioa...
-
Cluster metodo baten
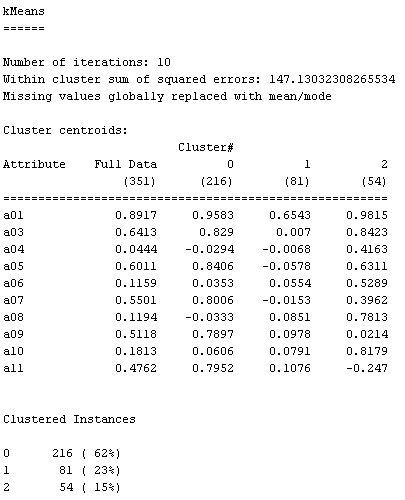
exekuzioak, era honetako "output"-ak sortzen ditu (ikusi beheko
irudia). "Food.arff" ez den
beste datubase batentzat egin dut.
Esplika itzazu agertzen diren
kontzeptuak, zuk egindako "food.arff"-rentzako clustering-ean, eta klase
teorikoetako materiarekin erlazionatuz: "number of iterations", "cluster centroids",
"full data", "clustered instances".
"Food" datubasearen kasuan, zenbat
zutabe daude "centroids"-etan? Zerekin du erlazioa "centroids"-eko
zutabe bakoitzak (hau da, ulertu emaitzen "matrize" horretan agertzen
diren datuak zer diren)?
-
Exekuzio bakoitzak WEKA-ren "Result-list"-en
(ezker aldean) emaitzaren hainbat propietate sortzen ditu: "right-click" eginez azken exekuzioan, emaitzaren
"Visualize
cluster assignments" propietatea interesgarria da.
-
lehenik, ulertu koloreek zer
adierazten duten.
-
"X ardatzean"
janariaren izena kokatu ("Name"), eta "Y ardatzean" beste
aldagai bat (adibidez, "proteina" kopurua); eta horrela ikus daiteke
zein cluster-etan multzoratu duen janari bakoitza; eta cluster bakoitza
zein janari bereziekin osatuta dagoen ikus dezakezu.
-
"X" ardatzen kokatu
du janari bakoitza, "food.arff" fitxategian janariek duten ordena
jarraituz. Baina janari bakoitza zein den identifikatzeko, soilik
janariaren izenaren ("Name") lehenengo letrak agertzen dira: zein janari
den identifikatzeko trukotxo bat izan daiteke "food.arff" fitxategi
textu editorearekin irekita izatea, eta datu matrizea osoki
ikustea jakiteko zein den janari bakoitza: hau da, aldi berean izan
irekita 2-D grafika eta datuen matrizea. Ez da oso "GUI" ("graphical
interface") erakargarria, baina tira...
-
"X" eta "Y" ardatzetan beste
bi edozein aldagai kokatuz gero (e.g. "Fat" eta "Calcium"), eta koloreak
erabiliz cluster-a adierazteko, janari eta cluster desberdinak nola
kokatzen diren 2-D grafika horretan ikus daiteke.
-
Ohartu zaitez non grafika
horien, kasuen gainean klikatuz, kasuari buruzko informazio zehatza agertzen dela
leiho berri batetan: kasuaren aldagai guztien balioa.
-
Proba ezazu hainbat cluster-multzo
kopuru desberdinekin (2 edo 3, gehienez), "eta gehien konbenzitzen" dizunarekin geratu.
Aukeratu duzunerako, agertu:
-
gogoratu janari guztiak
haragia edo arraia oinarritzat dutela: haragia oinarritzat duten kasu-janari guztiak cluster berberean sartu ditu?
-
cluster berdinean arrai eta haragia oinarritzat duten janaririk al daude?
hau da, "nahastutak" al daude cluster-en batetan haragia eta arraia
oinarritzat duten jakirik?
-
bere cluster-eko "centroide"-tik "urrun" dagoen kasurik al dago, hau da,
"outlier" antzekorik?... era honetako galderek lagunduko dizute ulertzeko egindakoa, eta
sorpresarik dagoen espero zitekeenarekin konparatuz. Probatzen joan
beharko zara grafika desberdinak, aldagaiak aldatuz. Ohartu zaitez
cluster-ak egin direla janarien "fat", "calcium", eta erako aldagaiak
erabiliz.
-
Ez da "automatikoa" izango, aurre-informaziorik
edo "intuiziorik" edo aditu bat izan gabe, aldez-aurretik jakitea zenbat
clusteretan ("number of clusters")
banatzea janari-elikagaiak. Teoria eta lan asko dago honen inguruan,
baina konklusio definitiborik ere ez. Ez dago neurri edo metrika zehatz
bat hori aurre-erabakitzeko, batzutan intuizioa da onena, jakiteko zenbat cluster-etan
hobe den banatzea gure kasuak non: cluster bateko kasuek antzekotasun
handia dute beraien artean (aldagaien balioen arabera), eta cluster desberdinetakoek ordea
antzekotasun oso txikia. Hau da kriterio numerikoa: hala ere, ahal
denean "intuizioa" erabilia (hori eskatzen dizuet) ez da batzutan
aukerarik txarrena...
-
Internet-en "k-means" (clustering
banatzailea) on-line egiteko demo anitz daude:
-
http://nlp.stanford.edu/~danklein/demos/constrained-clustering-demo.shtml
oso erraza da bere erabilpena. 2-D puntuak kokatu "Data point"-en klikatu eta gero (baita
ere "Data Set"-en klikatuz puntu hodei bereziak kokatzen ditu). "Options"-en
aukeratu: "cop k-means" metodoa eta cluster kopurua. "Cluster"-en
klikatu eta ikasitako cluster-ak koloreztatutak daude. Ulertzen al duzu
zer diren "must-link" eta "cannot-link"?
-
http://www.cs.washington.edu/research/imagedatabase/demo/kmcluster/
webgunean clustering-a egiten du eskeintzen dituen imaginen ezaugarrien
gainean: imagina aukeratu eta aurrera. Clustering-aren bidez, imaginaren
"region" desberdinak lortzen dira. Ohartu leio berri bat sortu duela "region"
hauekin.
-
WEKA-ren azken bertsioak
badu "clustering hierarkiko" metodo bat. Probatzen egon naiz ordea eta
dendogramak ez dira ondo irudikatzen, ez dago oso landuta oraindik...
Ondoko
loturan eskeintzen den "demoa" landuagoa dago: "X" ardatzeko balioa
soilik hartzen du aldagaitzat puntuak (kasuak) "clusterizatzeko"
(hau da, kasuek dimentsio bakarra dute, aldagai bakarra), pausuz
pausu ("Step") bi kasu hurbilenak lotuz dendograma eratuz. Ulertuko
duzulakoan nago, bestela galdetu bildurrik gabe.
[Galdera 12 -- Galdera hau martxoaren
18-ko laborategian burutu behar da -- Aldagai aukeraketa]
Gai honi dagokion teorian ikusi ahal
izan duzu sailkapen gainbegiratuko problema batetan aldagai iragarle guztien "garrantzia"
berdina ez dela. Aldagai iragarle "redundanteak" (beraien artean oso antzekoak
direnean) edo klasearekin garrantzi-gabekoak (erlaziorik ez dutenak iragarri
nahi dugun klasearekin), sailkatzailearen asmatze tasa murriztu dezakete. WEKA-k,
bere "Select
Attributes"
pestañaren bidez, aldagai aukeraketako eragiketak egiten ditu: gure azkeneko
sailkatzailea aldagai gutxiagorekin eraikitzeko, jakiteko zeintzuk diren aldagai
interesgarrienak problema batetan, asmatze tasak hobetzeko, eta abar.
Teorian ikusi izan duzun bezala,
aldagai aukeraketaren problema hau ebazteko forma erraza bat “filter”
tekniken bidezkoa da, non aldagai iragarleen ranking-ordenaketa
bat egiten dute "filter" teknika hauek: ordenaketa honek isladatzen du,
handienetik txikienera, aldagai iragarle bakoitzak iragarri nahi dugun
klasearekin duen korrelazio maila.
"Filter" metrika desberdin asko daude ("Select Attributes" pestañan, "Attribute
Evaluator"-en barruan), korrelazio maila hau kalkulatzeko. WEKA-k eskaintzen
dituenen artean, hauetako 3 Informazio Teoriarekin erlazio estua dute: hau da "entropiaren"
kontzeptuarekin ("H" deitzen dio ere WEKA-k) (sailkapen zuhaitzetan ere ikusi
izan duguna):
"Gain Ratio",
"Info Gain" eta "Symmetrical
Uncertainty". Aukeratu
hauetako bakoitza, eta "More" botoian sakatu ikusten erabiltzen duten formula
aldagai iragarle bakoitzaren korrelazioa kalkulatzeko klasearekiko: uler ezazu
bakoitza, erraza dela uste dut. Chi-karratu metrika ere badago lan berbera
egiteko (beharbada Estatistikatik gogoratuko duzu).
Ondokoa egin:
-
gure betiko lan azpidirektoriotik 15 aldagai
iragarle baino gehiago dituen datubasea aukeratu: uler ezazu bere lan
problemaren natura.
-
aldagai iragarleen korrelazio ranking bat egin
ezazu nahi duzun 3 metrika hauetako batekin: bere expresio-formula erakutsi
(erabiltzen duena aldagai eta klase arteko korrelazioa kalkultzeko).
Ranking-aren ezkerreko zutabean agertzen den balioa iragarle bakoitzaren
klasearekiko korrelazio maila da: metrikaren balioen arabera ranking-a
ordenatzen du.
-
konproba ezazu ranking-aren goi parteko aldagaiek ("top ranked features")
sailkapen zuhaitz bat eraikitzerakoan honen goi nibel garrantzizkoenetan
agertzen direla.
-
K-NN bizilagun hurbilenaren
sailkatzaile bat eraiki ezazu (zuk nahi duzun "k"-ren balioarekin), non
soilik "top-5" ranking-eko aldagaiekin: aldagai iragarle guztiekin ikasitako
sailkatzailea baino asmatze tasa hobea/txarragoa al du? Estima itzatzu
asmatze tasak 10-fold cross-validation bidez.
-
aurrekoaren berdina egin eta
erantzun, baina orain "top-10" iragarlentzat.
-
aurreko bi pausu berdinak egin,
baina K-NN sailkatzaile baten ordez, naiveBayes sailkatzailearentzat.
Diskutitu emaitzak.
-
edozein hiru ranking metrikekin ikasitako ordenazioa-ranking-a berdina al
da? izan beharko zen? zergatik?
[Galdera 13 -- Galdera hau martxoaren
18-ko laborategian burutu behar da -- Data mining-en aplikazioak]
Hurrengo loturetan nere
atentzioa deitu duten bi artikulu dibulgatibo batzuk daude,
"Data Mining-aren" hainbat aplikazio ulerkor aipatuz:
-
data-mining-eko tekniken
erabilera sare sozialetan, eta politikan egokituta, Obamaren kanpainan. [lotura]
-
data-mining-eko tekniken
erabilera anti-virus eta anti-spam aplikazioetan. [lotura]
Gainetik eman begirada bat bi artikulu-multzoei. Gero, horietako bat aukeratu. Aukeratutakoarentzat, rakurri eta hurrengo galderei erantzun,
laburki (bi artikulu-sortentzako egin ezkeroz lana, kontutan hartuko dut notan):
-
ezinbestekoa: zein da ebatzi nahi duen problema (predizitu
nahi duen gertaera-aldagaia)? zure ustez, zein balio hartu ditzake klase-aldagaiak
(imaginazioa bota...)?
-
ba al dute erabilitako aldagai prediktoreek
informazio nahikoa predikzio ziurrak egiteko? uste al duzu kasu-exenplu nahiko izango al ditugula
modelo ziurrak-solidoak eraikitzeko-ikasteko?
-
nondik eta nola jasoko ziren
datuak? hau da, antzematen al duzu "non dauden" datuak, hau
da, "nondik ateratzen" diren datuak, non dagoen "datu matrizea"?
-
zergatik da beharrezkoa "data mining" egitea,
datu analisia? ez al dago gizaki jakitunik ("domain expert") non ziurtasun osoz klasifika
ditzaken kasu berriak? edo datu "gehiegi" al dira "begiz analizatzeko"?
-
eta abar... zuk nahi dituzun apreziazio
eta detaileak jorratu... erabilgarria mundu errealean? antzeko
aplikazioak ezagutzen al dituzu: imagina ezazu eta proposatu bat?
[Galdera 10 -- Galdera hau martxoaren
11-ko laborategian burutu behar
da -- Sailkatzaile Bayestarrak, "naive Bayes"-etik aurrera, k-db erako estruktura Bayestarrak sortzen WEKA-rekin, eta ulertzen
probabilitate kondizionatu taulak]
Goazen hastea errepasatzen naive Bayes, TAN ("Tree
Augmented Network") eta "k-db" erako sailkatzaileak teorian.
WEKA-n ez dago
zehatz-mehatz Sahami-ren "k-db" teknika berdin berdina inplementatuta,
hau da, klase teorikoetan ikusi dugun berbera.
Ordea,
"Bayes" sailkatzaile gainbegiratuen familiaren barruan ("Classify"
pestañan), "BayesNet"
sailkatzaileak aukera asko ematen dizkigu. Bere parametroak ikus itzazu
klikatuz negritaz dagoen bere izenaren gainean. Parametro horietako bat "search
algorithm" da: honen bidez, era eta konplexutasun desberdin askotako
estruktura Bayestarrak "bilatu" ("search") daitezke, TAN
eta k-db egituretara hurbilduz.
"Search" parametro honen aukeratako bat "K2" teknika da (Himalaya-ko mendi tontor ezagunari omenaldia eginez,
hau da, pausuz pausu sortuko bait du soluzioa, "greedy" eran,
erlazioak-geziak aldagaien artean banan banan gehituz). K2 teknika honek sare Bayestar eta sailkatzaile Bayestar mota desberdinetakoak
eraiki ditzake.
Horretarako, K2-ren parametroak ikus itzazu bere izenaren gainean klikatuz.
Horietako bat "maximum number of parents" da. Ikusi parametro honen
explikazioa:

Hau da, beti dependentzi gezi bat jartzen du
klasea eta aldagai iragarle guztien artean.
Hortik aurrera, "maximum number
of parents" parametroari 2-ko balioa emanez, "zuhaitzera zabaldutako naive
Bayes" ("tree augmented naive Bayes") estrukturak sor daitezke.
Eta parametro honi 3 edo balio altuagoak emanez, k-db (k-menpekotasuneko
sailkatzaile Bayesiarra) erako estrukturak.
Hurrengo lanak egiteko "Hepatitis.arff"
datubasea aukeratu.
K2 algoritmoa aukeratuta,
"Maximum number of parents" parametroari 2-ko balioa emanez, "TAN
- zuhaitzera zabaldutako naive
Bayes" ("tree augmented naive Bayes") estruktura sor ezazu.
Aukeratu eta eraiki ezazu dagokion
sailkatzailea. Eraikitako estruktura grafikoa (hau da"zuhaitz" estruktura)
ikus ezazu "Result
list"-en propiedadetan ikusiz bere "Visualize graph". Ohartu zaitez
eraikitako grafo-estrukturaz, non, klase aldagaiak kondizionatzen ditu
aldagai iragarle guztien balioak: eta gero zuhaitz erako estruktura
eraikitzen duen aldagai iragarleen artean (hau da, aldagai iragarle bakoitzak beste
aldagai iragarle bat du gehienez guraso bezala estrukturan -- klaseaz aparte).
"Malaise" ("ezinegona") aldagaiaren (sintomaren) gainean klikatuz gero,
ondoko pantalla atera beharko zaigu:

Atera zaigun taula, "Probability
Distribution Table for MALAISE", ezinbestekoa da ulertzea.
Taula horretan, geroago k-db sailkatzaileak sailkapena egiteko, "p(klasea |
kasu_berria)" kalkulatzeko, ezinbestekoak diren hainbat probabilitate daude:
naive Bayes-ek erabiltzen zituenaren antzekoak, baina pixka bat
konplexuagoak.
"Malaise" aldagai iragarlearen probabilitate banaketaren "argazkia" da, estrukturan
dituen bi gurasoen kondizio-pean ("Class"-klasea eta "Fatigue": ikusi
taularen
ezkerreko parteko bi zutabeak).
"Malaise" aldagaiaren probabilitate banaketa agertzen da,
bere gurasoen balio konbinaketa guztietarako: horregatik, lau probabilitate
banaketa daude (ohartu ilara bakoitzean bi probabilitateen batura 1 dela),
guraso bakoitzak bi balio posible dituelako. Horrela, adibidez:
p(Malaise=no | Class=die , Fatigue=yes) = 0,242
p(Malaise=yes | Class=die , Fatigue=yes) = 0,758
Erantzun, laburki:
-
Eman itzazu falta diren beste 6 probabilitateak, p(Xi=xi
| Class=class, Xj=xj) forman, zehaztuz bakoitza zein
aldagai eta baliori dagokion.
-
Zergatik esaten da ilara bakoitza "probabilitate banaketa kondizionatu"
bat dela? Zergatik batu
behar dute "1" ilara bakoitzeko balioek?
-
TAN-erako estruktura batek,
aldagaien artean dauden "erlazio hestuenak" isladatzen ditu gezien bidez:
aldagaien artean geziak jartzeko aukera asko zeuden, baina soilik gutxi
batzuk jarri ditu. "Malaise"-ren kasuan zentratuz,
dauden 4 probabilitate banaketak ("Probability distribution Table"-ko 4
ilarak) kontutan hartuz, horietako zeintzuk izan dute eragin gehiago K2
algoritmoak erabakitzeko dependentzi geziak "Class" eta "Fatigue"-tik "Malaise"-ra? Azken ilara eta azken-aurreko distribuzio banaketak oso desberdinak dira...
-
Aurreko galderarekin
erlazionatuz, noiz dugu "informazio gehiago "Malaise"-ren balio posibletaz: azken ilararen
kasuan (Class=live eta Fatigue=yes, direnean) edo azken-aurreko ilararen kasuan (Class=live
eta Fatigue=no, direnean)?
-
"Malaise"-z jarri dudan adibideaz
aparte, bilatu eraikitako TAN estrukturan beste adibide bat. Eta explikatu
eta arrazonatu antzeko forman, ikusiz bere "Probability distribution Table".
"Maximum number of parents" parametroari 3-ko balioa emanez,
"3-db" (3-mendekotasuneko sailkatzaile
Bayestarra) estruktura sor ezazu, non aldagai iragarle batek gehienez 3
aldagai guraso (klasea derrigorrez, eta beste bi iragarle algoritmoak aukeratuta) izan ditzake estrukturan, bere balioak kondizionatzen
dituztenak. "Result
list"-en propietatetatik bere estruktura ikus ezazu ("Visualize graph").
Ohartu zaitez "Bilirubin" aldagai iragarleak 3 guraso dituela: "Class", "Anorexia" eta "Varices" (gibelean
barizeak izan edo ez). Bilirubinaren balio altua izatea ez da
izaten sintoma ona medikutzan... "Bilirubin" nodoan (aldagaian) klikatu
eta bere "Probability Distribution Table" erakutsi. Lehenengo,
taula ikusiz (zutabetako balioak), ohartu zaitez
WEKA-k erabaki duela bi balio diskretotan diskretizatzea (sare Bayesiar
hauek soilik aldagai diskretoekin eraikitzen ditu WEKA-k) "Bilirubin"-en balio jarraiak (-infinitotik 1'65-ra; eta 1'65-tik infinitora).
Erantzun
ondorengo galderei, "Probability Distribution Table for BILIRUBIN"-en
inguruan:
-
zenbat ilara ditu "Bilirubin"-en probabilitate banaketa agertzen duen taula honek? Zergatik daude esan duzun ilara kopurua?
-
idatz itzazu agertzen diren "p(Bilirubin | Class, Anorexia,
Varices)" probabilitate guztiak, banan banan, klase eta aldagai
iragarle konbinazio posible guztietarako (adibidez, zein izango zen "p(Bilirubin=between
1'65 and infinite | Class=die, Anorexia=no, Varices=yes)" probabilitatearen
balioa? (eta beste guztiena ere eman).
[Galdera 11 -- Galdera hau martxoaren
11-ko laborategian burutu behar
da -- Data mining orokorrean]
Kurtsoa jadanik aurrera doa, eta hasieran sorpresa bat
izan ziteken disziplina ("data analisiaren" rol-a gure gizartean), jadanik ez
da.
Gustatuko litzaidake jakitea irakasgaiarekin hasi eta asteak aurrera joan ahala,
zure inguran antzeman izan dituzula non dauden, non egon daitezken datu
analisiaren hainbat aplikazio.
Horrela, Internet-en topatu duzun eta datu
analisiarekin zerikusi hestua duen webgune bat erakutsidazu, eta komentatu eta
deskribatu:
-
Zein datu analisi aplikazioa
deskribatzen du?
-
Zehaztu: zer da sailkatu nahi den
gertaera (gure klase aldagaia)? Hau iragartzeko zeintzuk dira aldagai
iragarleak (laburbilduz)?
-
"Ez jakintasuna" ("uncertainty")
al dago eremu horretan, hau da, ez al dago giza aditurik zehazki, beti eta
azkartasunez iragarri nahi duguna emango diguna?
-
Zein enpresa/taldek plazaratzen du
aplikazioa? Zein interesekin, zein etekin espero du?
-
Beste zure komentarioetara irekita...
[Galdera 8 -- Galdera hau martxoaren 4-ko laborategian burutu behar
da -- Sailkatzaile Bayestarrak, "naive Bayes"]
Errepasatu
Sailkatzaile Bayestarren gaiko gardenkiak.
Bereziki ariketa egiteko: 6-tik 10-erako gardenkiak erakusten dute naive Bayes
sailkatzailearen funtzionamendua, Bayes-en Teoremaren sinplifikazio gisa.
Ulertu bere teoria: ikusi bere asuntzio nagusia dela aldagai iragarleak
(Xi), klasea ezagututa (C=c), beraien artean independienteak direla.
Suposa dezagun etiketatu gabeko kasu berri dugula, "kasu_berria=(X1=x1,
X2=x2, ..., Xn=xn)". Zein izango da bere "C" klasearen balioa?
Gogoratu apunteetan nolakoa den p(C=c|X1=x1,
X2=x2, ..., Xn=xn)
kalkulatzeko formula. Hortaz erabiltzen dituen estatistikoak, p(Xi=xi|C=c)
eta p(C=c): p(C=c|X1=x1,
X2=x2, ..., Xn=xn)
kalkulatzeko.
Hau da, asuntzio hau erabiltzen du kasu
berri batentzat, (X1=x1,
X2=x2, ..., Xn=xn), klasearen balio posible bakoitzarentzat kalkulatzeko bere
"a-posteriori" probabilitatea,
"p(C=c|kasu_berria)=p(C=c|X1=x1,
X2=x2, ..., Xn=xn)"
eta C-ren balio guztietarako aurrekoa kalkulatuz, "p(C=c|kasu_berria)" handienarekin geratuko gara, C=c*, klasea
iragartzeko kasu honentzat.
Goazen ariketa bat egitea "Hepatitis.arff"
datubasearekin: lehenengo hau ireki textu editorearekin eta laburki, ulertu
problemaren natura (klasearen balio posibleak, aldagai iragarle batzuk...).
Problemak, hepatitis-a duten gaixoen pronostikoa iragarri nahi dute ("pronostiko
txarra badute"--"die" edo "pronostiko ona"--"live").
Goazen bakarrik bere ondoko aldagaiekin lan egitea (uler ezazu beraien
esanahia):
"fatigue" (nekea), "malaise" (ezinegona, "malestar"),
"anorexia", "liver_big"
(gibela haundituta); eta noski, klasea - gaixoaren pronostikoa ("die" edo "live"
balioak ditu, hau da, gaixo hil edo bizirik irauteko pronostikoa egiten den). Beste aldagai guztiak ezaba
itzazu (preprocess leioa WEKAn -- aukeratu eta remove). Geratu den aldagai bakoitzaren
gainean klikatuz, ulertu itzazu histogramak eta bere koloreak ("Preprocess"
leihoan, behe eskubi partean).
Orain, 4 aldagai iragarle horiek erabiliko ditugu "Klasea
(die / live)" iragartzen saiatuko den naive Bayes sailkatzaile bat sortzeko.
Aukeratu WEKA-n: "Classifier -- Bayes -- NaiveBayesSimple". Sailkatzailea eraiki eta saiatuko
gara ulertzen "Classifer output" eskubiko partean agertzen zaigun
textua, hau da,
naive Bayes sailkatzaileak erabiltzen dituen estatistikoak "p(C=c|kasu_berria)" kalkulatzeko.
Output horren
parte bat hartuko dut eta esplikatuko dut (ikusi beheko irudiko ezkerreko
partea), eta honen antzekoa izango da (eskubiko parteko irudia naive
Bayes-en beste problema batentzako irudia da soilik, besterik ez, ez egin
kasurik, baina problema erreal batekoa da):
|
=== Classifier model (full training set) ===
Naive Bayes (simple)
Class DIE: P(C) = 0.21019108
Attribute FATIGUE
no yes
0.08823529 0.91176471
.................................................
|
 |
Lehenengo, klase bakoitzaren "argazki" bat
ateratzen digu (lehenengo "die" klasekoentzat, gero "live" klasekoentzat) datubaseko kasu guztientzat.
Lehenengo,
"Die" klasearen a-priorizko proportzioa (hau da, zenbat "die"
klaseko kasuen proportzioa) datubasean (output-ean
beherago
dago "Live" klasearen output-a).
Gero, Xi aldagai iragarle
bakoitzarentzat, "p(Xi=xi|C=c)" estatistikoen balioak erakusten dizkigu:
adibidez, "Class=Die" kasuentzako (klasearen
balio honen proportzioa datu basean p(Class=die)=0.2101), "nekea"
("Fatigue") somatu
duten probabilitatea 0.911 da, p(Fatigue=yes | Class=Die) = 0.911; eta "nekea"
somatu ez dutenen proportzioa p(Fatigue=no | Class=Die) = 0.0882 da (bien
batura 1 izatea, ez da?).
Estatistiko eta proportzio guzti hauek datubasetik
kalkulatuak izan dira!! Hepatitis.arff-ren
155 kasuetan!! Ez ditu asmatu!!
Eta hauek erabiltzen ditu kasu berri bat sailkatzeko eta p(C=c|X1=x1,
X2=x2, ..., Xn=xn)
kalkulatzeko.
Zuretzako: ateratako "Classifier output"-aren gainean,
markatu ezazu zein den "p(Xi=xi|C=c)"
bakoitza, aldagai iragarle oro (Xi) eta klasearen balio
guztietarako.
Saiatu
guzti hau ulertzen, eta demagun kasu berri bat etortzen zaigula (156. kasua:
zergatik diot hau??), non medikuak ez
dakien zein den bere klasea (ez dago ziur pronostikoa egiterako orduan), eta
erabakitzen da ikasitako "NaiveBayesSimple" sailkatzailea
erabiltzen dugula kasu hau sailkatzeko (pronostikoa egiteko). Kasu berria demagun ondokoa dela:
Fatigue = yes; Malaise = yes;
Anorexia = no; Liver_big = yes
Egin eskuz naive Bayes-en lana,
eta kalkulatu klase bakoitzaren "p(C=c|kasu_berria)"
(hau da, bai C=Die eta bai C=live- rentzako). Zein da naive Bayes-ek egiten duen apostua,
iragartzen duen klasea? Gogoratu klaseko apunteak eta teoria. Ulertzen al da naive
Bayes-en logika eta funtzionatzeko forma?
Egin berbera ondoko beste kasu
honentzat, kalkulatuz naive Bayes-en formula erabiliz, kasu berriaren "p(C=Die|kasu_berria)"
eta "p(C=Live|kasu_berria)":
Fatigue = no; Malaise = no;
Anorexia = no; Liver_big = no
Zure iritziz, nolakoak izango ziren
klasearen bi balioen artean indarrez desberdintzen-diskriminatzen lagunduko
digun Xi aldagai baten "p(Xi=xi|C=c)" probabilitate balioak?
Hau da, Xi-ren balio zehatz batentzako (adibidez, bere lehenengoa): nolakoak
izan beharko ziren beraien artean "p(Xi=lehen_balioa | C=Die)" eta "p(Xi=lehen_balioa
| C=Live)" probabilitateak? Antzekoak, oso desberdinak? Sailkatzailea
eraikitzeko erabili ditugun lau aldagaietatik, erakutsi aldagai bat (eta bere
balio bat) non aurrekoa indarrez gertatzen den.
Eta nolakoak izango ziren beraien artean "p(Xi=lehen_balioa | C=Die)" eta "p(Xi=lehen_balioa
| C=Live)" baldin eta EZ bagaituzte laguntzen problemaren bi klaseen artean
desberdintzen-diskriminatzen?
Naive Bayes sailkatzaileak, etiketatutako kasu
guztiekin eraikitzen duen modeloan zentratu gara ariketa guztian zehar: ez zaigu
axola ariketan zehar bere asmatze tasa altua edo baxua den (ez diogu
erreparatuko galderan WEKA-ren "Test options"-en aukeratutako asmatze-tasa
estimatzeko metodoan: hold-out, balidazio gurutzatua...). Erabili dugun
datubasea txikia izango da (kasu gutxitakoa), baino handiagoa balitz ondokoa "kritikoa"
izango zen, konputazio denborak handitzeko arriskuarekin: hau da, asmatze tasa
estimatzea axola ez bazait, WEKA-ren exekuzio azkarrago izateko:
-
zein "Test options"-eko aukera
hartuko dut?
-
zenbat modelo eraikitzen dira
"cross-validation 10 geruzekin" klikatzerakoan? (Pista bat emango dizut:
guztira, ez dira 10... zergatik, zeintzuk dira?)
-
eta "hold-out" (percentage-split
66%-33% klikatzerakoan)?
[Galdera 9 -- Galdera hau
martxoak 4-ko laborategian burutu behar da -- Irakurketak --
Ikasketa Automatikoaren aplikazio errealak]
Hurrengo loturetan nere
atentzioa deitu duten bi artikulu dibulgatibo batzuk daude,
"Data Mining-aren" hainbat aplikazio ulerkor aipatuz:
-
"sport's
injuries prediction" by mean of neural network. Nola
Milan AC taldean, sare
neuronalak erabiltzen dituzten betebehar honetarako. Sare neuronalak,
sailkapen gainbegiratuko beste teknika da, kurtsoan ikusiko ez duguna:
horretaz "abstraitu" zaitez, gutxienekoa da.
Milan AC club-aren
web-ean bereziki ikusi "Artificial Intelligence in the service of sport"
atala.
-
"mining
for cheap flights": askotan ziur pentsatu dugula noiz den momenturik
onena-merkeena hegaldi bat erosteko. Artikuluan agertzen den konpainia, "Farecast",
orain dela gutxi entzun nuen Microsoft-ek erosi duela. Ohartu zaitez aurreko
lotura Microsoft-en "Bing" bilatzailearen barruan dagoela, bere aplikazio
bat bezala: eta hegaldietaz aparte,
hotelentzako
antzekoa egiteko aukera du ere bai (ohartu zaitez "Bing" bilatzailearen
loturaren beheko partean, bai "flights" eta "hotels" aukerak dituela).
Gainetik eman begirada bat bi artikulu-multzoei. Gero, horietako bat aukeratu. Aukeratutakoarentzat, rakurri eta hurrengo galderei erantzun,
laburki (bi artikulu-sortentzako egin ezkeroz lana, kontutan hartuko dut notan):
-
ezinbestekoa: zein da ebatzi nahi duen problema (predizitu
nahi duen gertaera-aldagaia)? zure ustez, zein balio hartu ditzake klase-aldagaiak
(imaginazioa bota...)?
-
ba al dute erabilitako aldagai prediktoreek
informazio nahikoa predikzio ziurrak egiteko? uste al duzu kasu-exenplu nahiko izango al ditugula
modelo ziurrak-solidoak eraikitzeko-ikasteko?
-
nondik eta nola jasoko ziren
datuak? hau da, antzematen al duzu "non dauden" datuak, hau
da, "nondik ateratzen" diren datuak, non dagoen "datu matrizea"?
-
zergatik da beharrezkoa "data mining" egitea,
datu analisia? ez al dago gizaki jakitunik ("domain expert") non ziurtasun osoz klasifika
ditzaken kasu berriak? edo datu "gehiegi" al dira "begiz analizatzeko"?
-
eta abar... zuk nahi dituzun apreziazio
eta detaileak jorratu... erabilgarria mundu errealean? antzeko
aplikazioak ezagutzen al dituzu: imagina ezazu eta proposatu bat?
[Galdera 6 -- Galdera hau
otsailak 25-ko laborategian burutu behar da -- Laugarren gaia: Sailkapen
zuhaitzak, inausi ("pruning") edo ez]
Errepasatu sailkapen zuhaitzetako gaiko ondoko kontzeptuak
gardenkietan:
-
zuhaitzen ikasketa algoritmo orokorra: 8.
gardenkia
-
C4.5 algoritmoak zuhaitzaren erpinetan aldagai
bat aukeratzeko irizpidea: 13. gardenkia
-
inausketa ("pruning") kontzeptua: 13, 14 eta
15. gardenkiak
"Breast-cancer.arff"
datubasea hautatuz, lehenengo ulertu laburki tratatzen ari den problema (bereziki,
iragarri beharreko klasearen balioak, eta hau iragartzeko aldagai-iragarleak).
WEKA-ren C4.5 metodoarekin (WEKA-n J48 izena du,
"trees" familiaren barruan) bi
sailkapen zuhaitz eraiki:
J48-ren "unpruned" parametroak inausketa
aktibatu edo desaktibatzen du. Kasu guztiekin eraikitako bi arbolen bertsio grafikoak ikusiz ("Result
list"-en propiedadeak, arratoiaren eskubiko botoiaz), erantzun:
-
eraikitako bi arbolak desberdinak al dira?
zein neurriraino? tarteko aldagai askotan? hosto kopuruan? WEKA-ren
emaitzaren textuzko output-ean bi balio daude: "number of leaves", "size
of the tree". Komentatu eraikitako bi arbolen arteko diferentziak.
-
arbola bakoitzarako, erantzun: nodo
kopurua (tarteko aldagai edo partizio kopurua), hosto kopurua.
Datubasearen aldagai prediktore original guztiak agertzen al dira arboletan?
-
Inausitako zuhaitzarentzat. Zer uste duzu agertzen dutela
hostoetako zenbakiek? Dezimalak ahaztuz, batu itzazu hosto bakoitzean
ezkerreko parteko zenbakia. Zer izan daiteke (ahaztuz dezimalak)
eskubiko zenbakia hosto bakoitzean? Gogoan izan zenbat kasu dauden guztira zure datubasean.
[Galdera 7 -- Galdera hau
otsailak 25-ko laborategian burutu behar da -- Ikasketa automatikoaren
aplikazioak -- K-NN sailkatzailea -- Recommender systems]
Web 2.0-ren adibide onenetakoak bezala, "Collaborative filtering", "social
bookmarking" edo "Recommender systems" izeneko teknikak orain dela urte
gutxi agertu dira sekulako indarrez Adimen Artifiziala eta Data Analisian.
Ikus ezazu
"Recommender systems"-en definizioa Wikipedian. "Recommender
systems"
oso ezagunak ditugu gure inguruan hainbat webgunetan:
Amazon, last.fm,
allposters.com,
StumbleUpon,
GoodReads, eta abar.
Nere gustorako, "recommender" landuenetako bat, benetan fina,
last.fm-rena da.

"Recommender systems"-en lan egiteko forma K-NN
(auzokide hurbilena) sailkatzailearen lan egiteko eratik ("algoritmkatik") oso hurbil dago,
erabiltzaileen arteko "distantziak" kalkulatzeko eran.
"Recommender systems"-ak saiatzen dira gure gusto eta preferentzi antzekoak
dituzten erabiltzaileak topatzen ("auzokideak"... hor dago K-NN-ren itzala),
guri proposatzeko hauei gustatu zaizkien (eta guk oraindik probatu ez dugun)
"aktibidade"-"adibideen" artetik, guk oraindik probatu-erosi
ez ditugunak. Hau da, ingelesezko "collaborative filtering", esanez, "denon
arteko jakinduriarekin egiten dugu aukeraketa"...
Orain dela urte batzuk lehen plazaratu zen "recommender"
adibidea
pelikulena izan zen.
Pentsa dezagun erabiltzaile talde bat gaudela, eta
hauetako bakoitzak ikusi dituen pelikulei puntuazio-balorazio bat ematen
dio. Noski, denek ez dituzte ikusi pelikula guztiak. Eta denak gogoz daude
jakiteko ea ikusi ez dituzten pelikuletatik, zein izan daiteken gustatzea
litekeena. Eta "recommender system"-ek, erabiltzaileok karteleratik ikusi
ditugun pelikuleei emandako puntuazioetan oinarrituta, saiatzen dira "gure
gustu antzekoak dituzten erabiltzaileak topatzen bere erabiltzaileen datu
base handi horretan". Eta horrela, oraindik ikusi ez ditugun eta gure "gustoetan
antzeko diren erabiltzailei" gustatu zaizkien pelikulak gomendatuko dizkigu
sistemak automatikoki. Pelikulen "recommender systems" ezagunena mundu
mailan netflix.com da, non urtero
txapelketa bat antolatzen dute non, beraien datuetan oinarrituta, nork
proposatuko dien "recommender systems"-eko algoritmorik onena:
http://www.netflixprize.com/,
with a $1 M award.
Ikusi ere 2011 urtean, datu
analisiko KDD konferentzian ("Knowledge Discovery from Datasets") proposatutako
datuen gaineko konpetizioa.
KDD-Cup'2011 from Yahoo! Music.
Egin beharrekoak, laburki komentatuz:
-
Komentatu eta laburtu itzazu galdera honetan jarri
dizkizuedan loturak-linkak.
-
Jarri ditudan
loturetatik, zein da atentzioa gehien deitu dizuna? Zergatik?
-
Zure iritzia eman: teknika hauek
erabilgarriak al dira? Erabiltzen al dituzu, bai zuk, edo zure
ingurukoek?
-
Eman ezazu Internet-en dagoen beste
adibiderik "recommender systems" dena. Deskribatu ezazu. Pila daude
eta zihurasko noizbait erabili izan dituzu.
-
Beste alor batetan
erabilgarria izan daiteken "recommender system" baten ideia eman,
laburtuz bere ezaugarri nagusiak.
[Galdera 4 -- Galdera hau otsailak
18-ko laborategian burutu behar da -- 3. gaia, sailkatzaileen ebaluazioa]
Errepasatu klase teorikoetako gardenkietan, 3.
gaian, sailkatzaileen asmatze tasa estimatzeko metodoak: estimazio ez-zintzoa, Hold-out metodoaren
hainbat exekuzio, k-geruzako balidazio gurutzatua.
Ondoko
azpidirektorioko datubase baterako, estimatu 5-NN (5 bizilagun
hurbilenen sailkatzailea, zuk nahi duzun bizilagunen boto-pisaketa erarekin)
sailkatzailearen asmatze tasa:
-
Estimazio ez-zintzoa (WEKA-ren "Use training
set" aukera).
-
Hold-out metodoaren exekuzio bakarrarekin (66%
training, 33% test).
-
Hold-out metodoaren 4 exekuzioekin (66% traing,
33% test) [ikusi beharko dugu "seed"-haziaren aldaketaren beharra...]
-
5-fold (geruza) balidazio gurutzatuarekin
(cross-validation).
-
10-fold (geruza) balidazio gurutzatuarekin
(cross-validation).
Zergatik ez dira emaitzak berdinak (izan beharko al
ziren...?)? 5 estimazio
formetatik, zeinetaz fidatzen zara gehiago (intuizioa erabili, soilik,
erantzuteko)?
[Galdera 5 -- Galdera hau otsailak
18-ko laborategian burutu behar da -- "Data Preprocessing" -- "Discretizing
attributes"]
K-NN sailkatzaileek bi motako
aldagaiekin lan egin dezakete auzokideen (bi kasuen) arteko distantziak kalkulatzeko
(errepasatu K-NN-ren 13. gardenkian, non aipatzen den nola egiten den bi kasuen
arteko distantziaren kalkulua),
aldagaiz-aldagaiko kenketa-distantzia kalkulatzerakoan:
-
aldagaiak "orden" izaera bat duenean ("ordinal"
edo "continuous" erabiltzen dira ere izendatzeko), hau da,
"orden" kontzeptu bat dagoenean bere balioen azpitik: aldagaiak normalizatu
eta gero (0-1 eremura eramanez), distantzi Euklidestarra erabiltzen da aldagai
horren bi balioen arteko distantzia kalkulatzeko. Era horretan,
distantzi maximoa 1 da, minimoa aldiz 0. Defektuz hau da ikasi
duguna klase teorikoetan.
-
baina zer egin aldagai
"nominalekin" (kolorea, adibidez): aldagaiek ez dutenean ordenik, "nominal" izenaz ere ezagutzen dira ("discrete" bezala ere): "izenek"
("nombres"-"nominal") definitzen dituzte bere balioak. Aldagai mota honentzat ezin da distantzia Euklidestarra
erabili bere bi balioen arteko distantzia kalkulatzeko: "zein da
gorriaren eta urdinaren arteko distantzia Euklidestarra?". Eta
honetako aldagaiekin, "overlap" izenez ezagutzen den distantzia erabiltzen da bere
bi balioen arteko distanzia kalkulatzeko:
-
bi balioak berdinak badira (A=A),
orduan distanzia 0 da;
-
bi balioak desberdinak badira
(A≠B), orduan distanzia 1 da.
-
"overlap" idea, oso sinplea baino, nahiz
eta beste aukera batzuk egon, ez dira tribialak.
Gure datuetako balio numerikoak-ordinalak dituzten
aldagaiak
diskretizatzea ezinbestekoa da ikasketa automatiko eta data mining-eko
aplikazio eta egoera askotan. Sailkatzaile mota askok ere ezin dezakete
balio numerikoekin lan egin, eta horrelakoak diren
aldagaiak diskretizatu behar dira. Ikertzaile eta aditu batzuk ere diote
aldagai bat hobeto "ulertu eta interpretatzen" dela bere balio diskretoekin.
Iritziak, anitzak, koloreak bezala.
Diskretizazioko adibide bat ondokoa izan daiteke, "adina"
aldagaiarentzat: bere zenbakizko balioekin lan egin beharrean (adibidez, 20
urte, 7 urte...), "adina" diskretizatu hainbat (4) tarte-eremu-"range"-"bin"-etan:
adibidez [0-tik,14 artekoak]→ "umeak"; [15-tik, 30-ra]→ "gazteak"; [31-tik,
70-ra] → "helduak"; [70-tik aurrera] → "zaharrak". Eta hemendik aurrera,
adina aldagaiarentzat: "umea", "gaztea", "heldua" eta "zaharra" balioekin
lan egin (4 kolore izango balira bezala).
Zenbakizko aldagai bat diskretizatu eta gero, bere bi balioen arteko
distantzia ezin daiteke jadanik era Euklidestarrean kalkulatu, eta "overlap"
erako distantzi batera jo beharko dugu. Zenbat izango zen ("zaharra" ken "gaztea")...?!?!?
Ondoko
azpidirektorioko "cars.arff" fitxategia kargatu WEKA-n.
Lehenago, textu bezala ireki-irakurri fitxategia, eta irakurri zein den
problemaren explikazioa, eta natura, ebatzi nahi duen problema eta dituen
aldagai iragarleak: fitxategiaren textuaren goiko partean dituzu azalpen
hauek (iragarri nahi den aldagaia, klasea, azkena, "origin of the car").
Fitxategi honek aldagai ordinal eta nominalak ditu, bi motatakoak.
"Discretize" preprozesuko teknikarekin lan egingo dugu: Preprocess → unsupervised → attributes. "Unsupervised" bezala ezagutzen da, klase (sailkatu-predizitu
nahi den) aldagaia erabiltzen ez duelako.
Diskretizazioa aplikatzeko: "Filter" → "Choose"
eta behin aukeratu eta gero, beltzez dagoen "Discretize" funtzioaren
izenaren gainean sakatuz gero: funtzio honen parametroak ikus daitezke eta
aldatu ("tune"). Informazio gehiago lor daiteke parametro bakoitzaren
inguruan "More" sakatuz. Behin parametroak "tuneatu" eta gero, "Apply"
sakatu funtzioa aplikatu izateko datuen gainean (pantallaren eskubiko
partean). Diskretizazioa aplikatu eta
gero eta bere eragina aldagaien balioen gainean ikusi eta gero, erantzun:
-
zer dira "bins" eta
"useEqualFrequency" parametroak? Sakatu "More"
botoia eta ikusi "useEqualFrequency" parametroaren aukerak: zein da diskretizazio
"Equal Frequency" eta "Equal
Width" metodoen arteko diferentzia nagusia? Pentsatu,
Internet-en ikusi, eta laburki esplikatu.
-
zein da sortu den
eragina aldagaien
balioetan diskretizazioa aplikatzerakoan? Ikusi WEKA-ren "Preprocess"
pestañako behe-eskubiko histograma. Zein "balio" ditu
orain, diskretizatu eta gero, aldagai bakoitzak (zer esan nahi dute "(23.5-26.4]" edo "(-inf-11.9]"
erako expresioek)?
-
"cars.arff" fitxategiko
zein aldagairi eragin die? Zeintzue ez eta zergatik?
-
K-NN sailkatzaile baten asmatze tasa
berdina al da diskretizazioa aplikatuta edo aplikatu gabe? Zergatik
(espero al zenuen)?
[Galdera
2 -- Galdera hau otsailak 11-ko laborategian burutu behar da -- Bigarren Gaia:
K-NN, "K-nearest neighbour", "k-bizilagun hurbilenen sailkatzailea"
-- 3. gaia: Sailkatzaileen ebaluazioa]
WEKA softwarearen IB1 ("instance-based 1") sailkatzaileak bizilagun hurbilena soilik erabiltzen du sailkapenarako
(1-NN):
klase ezezaguneko kasu berri bat etortzerakoan sailkatua izateko, sailkatzen
dugu entrenamenduko fitxategiko kasu "hurbilenaren" klasearekin. Ikusi gardenki
teorikoen bostgarrena.
K-NN erako sailkatzaileen familia atzitzeko WEKA-n, begiratu "Lazy" karpetaren barruan, WEKA-ren "Classify" moduluan.
(Ez erantzun orain, baina zer esan nahi du "lazy" ingelesez? Kurtsoa aurrera joan ahal
ikusiko dugu sailkatzaile familia honen izenaren zergatia).
IBk
sailkatzaileak ordea, etiketatu gabeko kasu berriaren klasea predizitzeko,
kasu honen entrenamendu fitxategian dauden "k" bizilagun hurbilenak
konputatzen-bilatzen ditu lehenago. Hori egin eta gero, klase teorikoetan ikusi duzu
bariante asko daudela, IBk-ren parametroen balioen arabera eta K
bizilagunekin egiten ditugun "jokoen" arabera: ikusi teoriako gardenkiak.
Probak egiteko,
ondoko
azpidirektorioko eta bi klase-balio dituen zuk nahi duzun datubase
batekin probak egin eta kargatuta
izan WEKA-n.
IBk
sailkatzailearen ondoko parametroak esplika itzazu: "KNN", "distanceWeighting".
Nahiz eta klase teorikoetan ikusi, WEKA-k ez du ematen IBk sailkatzailean
aldagai iragarleak desberdinki "pixatzeko" aukera: bai ordea bozka eman behar
duen bizilagun bakoitzaren pixua.
WEKA-n, sailkatzaile baten parametroak
ikusteko eta esplikazio laburra ikusteko, klikatu metodoaren negritaz dagoen izenean, eta gero "More" botoia.
IBk sailkatzailearekin informalki probak egin, "KNN" eta "distanceWeighting" parametroen balioak aldatuz:
bizilagun kopurua aldatuz, bizilagunen-pisaketa forma aldatuz:
-
Esplika itzazu "distanceWeighting" parametroaren balio posible
hauek: "NoDistanceWeighting",
"Weight by 1/distance". Gardenki teorikoetan non agertzen da "Weight
by 1/distance" aukera? Ulertu ondo zer inplikatzen duen.
-
"Hold-out (%66
train, %33 test)" asmatze-tasa-estimazio metodoaren bidez ebaluatu
eraikitzen dituzun
sailkatzaileen barianteak: asmatze tasak aldatzen al dira parametro hauen ("KNN" eta "distanceWeighting") balioak
aldatzerakoan? Gardenki teorikoetan non agertzen da "Hold-out" estimazio
teknikaren esplikazioa?
-
Errepasatu gardenki teorikoetan "errore
matrizea", True Positive Rate (TPR)", "False Positive Rate (FPR)"
kontzeptuak: zein gardenkian agertzen dira? IBk sailkatzaile baten (zuk nahi
duzun parametro balioekin) eta "Hold-out" estimazio teknikaren exekuzio
batentzat, agertu aurreko kontzeptuek dituzten balio zehatzak WEKA-ren
exekuzio horretan.
-
Gardenki teorikoetan, non agertzen da "use
training set" estimazio teknikaren esplikazioa? Zer izena ematen diogu
gardenki teorikoetan? "Hold-out" estimazio
metodoak bueltatzen duen asmatze tasa, normalean, "use training set"
estimazio metodoarena baina baxuagoa al da? Zergatik uste duzu hori
gertatzen dela?
-
Zein da "use training
set" estimazio teknikak bueltatzen duen asmatze tasa IB1 sailkatzailearekin?
[Galdera
3 -- Galdera hau
otsailak 11-ko laborategian burutu behar da -- Sarrera -- Irakurketak --
Ikasketa Automatikoaren aplikazio errealak]
Artikulua irakurri eta gero, hurrengo galderei erantzun:
-
zergatik da beharrezkoa "data mining" egitea,
datu analisia? ez al dago gizaki jakitunik non ziurtasun osoz klasifika
ditzaken kasu berriak? datu "gehiegi" al dira "begiz analizatzeko"?
-
zein da ebatzi nahi duten problema (predizitu
nahi duten gertaera-aldagaia)?
-
ba al dute erabilitako aldagai prediktoreek
informazio nahikoa predikzio ziurrak egiteko? uste al duzu kasu-exenplu nahiko izango al ditugu
modelo ziurrak-solidoak eraikitzeko?
-
antzematen al duzu "non dauden" datuak, hau
da, "nondik ateratzen" diren datuak, non dagoen "datu matrizea"?
-
erabilgarria mundu errealean? antzeko
aplikazioak ezagutzen al dituzu?
-
eta zuk nahi duzun edozein komentario.
Gustoko eta motibagarria egin al zaizu irakurketa?
[Galdera 1 -- Galdera hau
otsailak 4-ko laborategian burutu behar da -- Sarrera, problemen aukeraketa]
Kurtsoa aurrera joan ahala, sakonago aztertuko dugu ikasketa automatikoan
erabiltzen den "UCI Machine Learning
Repository": ikasketa automatikoko teknika berriak testatzeko erabiltzen den
datubase multzo zabala: "view all datasets"-en klikatu. Datu base
bakoitzarentzat normalean bi fitxategi daude: bata "*.data"extensioduna non
kasu matrizea dugun, eta "*.names" extensiodunean aldagaien eta
deskripzioarekin.Gehienak, problema errealak, ikertzaile eta enpresetako
jendeak igotakoak.
Orain, ondoko
loturan, kurtsoan zehar erabiliko dugun WEKA softwarearen *.arff formatoan eta atentzioa deitu didaten hainbat
datubase daude, gainbegiratutako problema errealetan oinarritutak guztiak. Fitxategiak
textu editore sinple (e.g. Wordpad) batekin irekiz gero, bere goiko partean,
problemaren natura isladatzen du, bere ezaugarri nagusienak. Kurtsoan zehar egingo ditugun
ariketetan bai datubasea zuk aukeratu, edo nik proposatuko dizuet: normalean,
azpidirektorio honetako batekin. Asko
laguntzen du ulertzea tratatzen ari garen problemaren izaera.
Begirada bat eman gainetik fitxategiei: laborategian agertuko dizuedan bezala,
"%" sinboloaz hasitako lerroa komentarioa da, eta hauetan problemari buruzko
informazioa duzute ("relevant information", "past usage", "number of instances",
"class distribution", "attribute information"...) ("attribute", edo guretzako "aldagai
iragarlea"); komentarioak eta gero, lerro bakoitzean kasu bat, komen bidez
aldagai iragarleak eta klasea banatuz.
Gero, bi datubase aukeratu eta beraientzat hurrengo puntuak agertu:
-
agertzen duten problemaren natura,
oinarria, zergatia agertu
-
zein da burutu nahi den sailkapen
problema? zehaztu: zein da klasea ("problem class, class to be
predicted")? Labur explikatu klaseak har ditzakeen balio desberdinak,
eta klase-balio bakoitzarentzat dagoen kasu kopurua (klasearen balioen
distribuzioa)
-
ulertzen dituzun ahalik eta aldagai
iragarle ("attributes" deitzen zaie fitxategietan; edo "features", "predictors", "variables") gehienak labur
explika itzazu (baino gehinez 5-6). Zenbat aldagai iragarle ditu?
-
datubasearen problemaren inguruan
atentzioa deitu dizun beste edozein puntu: zergatik aukeratu dituzu
hauek eta ez beste batzuk? gustokoa duzu? interesantea?... zure
komentarioetara irekita.